Abstracts
Workshops | Papers | Posters
Opening Keynote | Museum Lecture | Club Lecture | Closing Keynote
conference page with schedule
Critical Editing I | Building Communities | Cultural Heritage | Social Editing & Funding | Publishing | Licenses | Critical Editing II
L
Workshops
Tuesday, 15 March 2016, 11 am – 4:30 pm
Future Publishing Models for Digital Scholarly Editions
- Michael Pidd
- Anna-Maria Sichani
- Paul Caton
- Andreas Triantafyllidis
Digital Editing Beyond XML
- Fabio Ciotti
- Manfred Thaller
- Desmond Schmidt
- Fabio Vitali
- Domenico Fiormonte
Future Publishing Models for Digital Scholarly Editions
Venue: Room 4.011
Organizers: Michael Pidd (HRI Digital) & Anna-Maria Sichani (DiXiT- Huygens KNAW)
Workshop description:
The aim of the workshop is to bring together digital editors, researchers, library and digital collections specialists, publishing professionals, marketing experts and entrepreneurs in order to discuss and further challenge the production, publishing and dissemination models for digital scholarly editions. The workshop will be ‘futurist’ in its thinking, aimed at rapidly developing innovative ideas about what digital scholarly editions should or could be like in the future.
Currently the majority of digital editions are produced within a project-based logic as “experiments”, a way to test what is possible within the new medium and to establish new ways for scholarship” (Pierazzo 2015, 204) and secondly as ‘products’ within the scholarly publishing and communication circuit, with distinct operational aspects or features. Nonetheless, there are many digital editions that remain constrained by the conventions of their printed counterparts. These approaches often cause headaches for editors or production managers in terms of development and sustainability planning and prevent digital editions from thriving as valuable digital scholarly resources in the long-term.
During the workshop we aim to discuss the value and challenges of digital editing from an operational perspective. The format of the workshop will consist of three short scene-setting talks followed by a process of discussion and rapid ideas generation by workshop participants. The themes covered during the workshop will include:
- project management – production workflows
- standards – tools – interoperability
- sustainability – preservation – reuse
- partnerships – collaborations
- formats – functionalities – distribution channels
- business models – monetization avenues
- rights and licensing – Open Access – citation mechanisms
- audience – market (demand-driven production, usability, evaluation and impact assessment)
The following speakers will present scene-setting talks:
- Michael Pidd, Director of HRI Digital at the University of Sheffield. Michael will talk about academic institutional models for creating and maintaining scholarly digital editions.
- Paul Caton, Senior Analyst at King’s Digital Lab, King’s College London
- Andreas Triantafyllidis (thinking.gr / vivl.io)
Draft timetable:
Morning session: 11am-12.30 pm
- workshop intro
- speakers presentations
- Q & A
Lunch break : 12.30-13.30 pm
Afternoon session: 13.30- 16.00 pm (with a 10 min coffee break)
- rapid ideas generation – groups
- overall discussion –final remarks
Digital Editing Beyond XML
Venue: Lecture Hall XII
Organizer: Fabio Ciotti (Tor Vergata)
Workshop description:
Digital scholarly editorial theory and practice over the past 25 years have been based primarily on the OHCO (ordered hierarchy of content objects) model of XML, particularly as embodied in the TEI (text encoding initiative) Guidelines. Although TEI/XML is a highly developed descriptive formalism whose use is now widespread, it suffers from many technical shortcomings and limitations. This workshop aims to introduce scholars and practitioners of digital scholarly editions to alternative rationales and practical solutions to the problems of digitisation and user interface design for cultural heritage texts.
Program:
11.00 – 11.15 Fabio Ciotti – Introduction and welcome
11.15 – 12.00 Manfred Thaller – What is textual variance in the eyes of a software technologist?
12.00 – 12.45 Desmond Schmidt – What would be possible without XML?
12.45 – 13.30 Fabio Vitali – The expressive power of digital formats: criticizing the manicure of the wise man pointing at the moon
14.30 – 15.15 Domenico Fiormonte – A response
15.15 – 15.30 Open Discussion
15.30 – 16.30 Laboratory: Desmond Schmidt/Domenico Fiormonte
Abstracts:
Manfred Thaller | What is textual variance in the eyes of a software technologist? | Slides
“Content and concepts must always govern technology.” There has probably never been a meeting of a Digital Humanities project, where some variance of this sentence has not been uttered. Nevertheless hidden quirks of digital technology have changed details of everyday behavior for a long time. People born in the fifties in central Europe have learned to write dates like March 15th 1955 as “15.3.1955” – and “15.03.1955” still looks strange to them. As students borne forty years later write the leading zero quite voluntarily, something has changed obviously. The reason is clear: For programmers using old fashioned languages like FORTRAN or COBOL processing “01.03.1980” has simply been more convenient, by orders of magnitude, than processing “1.3.1980”. So the effectiveness (we would never say: laziness) of a few thousand people can silently change the conventions used by millions.
Millions, who have been willing to accept, that “technology” required a specific behavior. Or possibly: Thinking it easier to accept technology as it is, rather than insist on changing it, as that would have meant bothering about its silent assumptions? In everyday life until today we accept the mystery, that software may soon be able to behave autonomous and intelligently, but understanding reliably that accented and not accented characters are for most purposes the same, still beats most systems. Here, too, a few silent assumptions about character encoding hide in the background.
If you refuse to look more closely at the assumptions behind technology, as irrelevant contentwise, you are not triumphing about technologists, you accept being dependent from them.
One assumption of information technology is, that a text is a linear sequence of characters. “Linear sequence” implies, that one character is preceded and followed by exactly one other. This means, that a construction, where an abstract textual object is derived from two concrete witnesses, which deviate from each other by exactly one character – say episcopus v. episkopus – can never be realized on the most simple level of software which is usually considered by programmers, but has to be realized by individual solutions within a specific technical system. Technical systems handling textual variation, therefore, are almost invariably incompatible to each other.
We will use this example to explore, what technological concepts would be needed, to embed an understanding of such variance so deeply into software, that software systems handling text would handle the variability of text as “naturally”, as they handle the (optional) transparency of case sensitivity today. This, in turn, we will use as a starting point for a short exploration, how the logical properties of the content of critical editions can be embedded into software in general.
Biography
Manfred Thaller, born 1950, holds a PhD in Modern History from the University of Graz, Austria and a PostDoc in empirical Sociology from the Institute for Advanced Studies, Vienna, 1978. He worked for twenty years at the Max-Planck-Institut for History in Göttingen, where he developed a general concept of applied computer science in the Humanities, having visiting professorships at the universities in Jerusalem, London and Firenze. Since 1995 he held a professorship in Hum in that field of at the University of Bergen, before moving in 2000 as Prof. of «Historisch Kulturwissenschaftliche Informationsverarbeitung» (Humanities Computer Science) to the University at Cologne, Germany, where his focus moved from research to teaching. Since the middle of the nineties he became more and more involved with digital libraries in the cultural heritage area, and later with digital preservation. As a result during recent years, he totally succumbed to obligations resulting from the membership in numerous committees and advisory boards. Retired since summer 2015, he still has obligations from that phase, is grimly determined, however, to withdraw into the ivory tower as soon as possible, ignoring research politics as well as DH hype and focus exclusively on his personal research interests.
Desmond Schmidt | What would be possible without XML? | Slides
The limits imposed by XML are well known, but what would be possible without it? If we want to share and collaborate we must rethink our approach to turning historical documents into digital editions for the Web and eBooks. We need Web-based interfaces for editing, analysis and annotation designed for the idiosyncrasies of our texts, which should be encoded in globally interoperable formats, rather than customised XML markup. Until we can think through what is needed and maintain it together we will continue to work in effective isolation, competing against one another, rather than working together.
The laboratory session will create a basic digital scholarly edition from a one-page text in multiple versions already transcribed in Italian, German or English of the participant’s choice, with a minimum of search, comparison, minimal markup editor and single version display tools.
Biography
Desmond Schmidt has PhDs in classics (Cambridge (1987) and information technology (University of Queensland 2010), and is an adjunct fellow in eResearch at the School of ITEE of the University of Queensland. He has worked on the Vienna Wittgenstein Edition (1990-2001), on Digital Variants at University Roma 3 since 2004, and on the Charles Harpur edition since 2012. His research interests include the development of user-friendly tools for digital scholarly editions, multi-version documents and text-to-image linking.
Fabio Vitali | The expressive power of digital formats: criticizing the manicure of the wise man pointing at the moon | Slides
In 1966, two italian computer scientists, Corrado Bohm and Giuseppe Jacopini, proved an important theoretical result, according to which all sufficiently complex programming languages are equivalent to each other in expressive power (by being equivalent to the expressive power of a Turing machine). Not only, the requirements for this equivalence are surprisingly modest: a sequencing instruction, a branching instruction, and a looping instruction.
Thus it well known in computing circles that the difference between important, classic languages such as Java or Python, Real Men™ languages such as assembler or C, hipster languages such as Scalia or CoffeeScript, or actual jokes such as Lolcode or Whitespace, lie not in their expressive power, which is the same for all, but in the convenience and friendliness of their syntax and constructs, a stylistic characterization no less. Stylistic differences are the grounds for the development of biased, pointless and nasty religious wars about the relative merits of these languages.
We are currently very much in a religious war regarding digital formats for data structures: plain text formats, HTML + embedded annotations (e.g. RDF/A), XML dialects, RDF collections and ontologies have their pugnacious defendants, harsh critics, and ultimately pointless skirmishes in a number of communities. Yet, their expressive power is similarly irrelevant: all these formats have exactly the same expressive power, as can be witnessed by the fact that all of them, ultimately, allow linearizations as plain text strings. The discussion is therefore on aesthetic, rather than substantive, differences between them, and particularly in the comparison between the qualities that are pre-existing in the language and those that one must construct explicitly: it bears repeating, one can ALWAYS bring them in any format, none is too complex to be unreachable.
We already know already some qualities: sequence vs. trees vs. graphs, embedding vs. stand-off, locality vs. globality, support of single vs. multiple vocabularies, etc. Switching from one format to another requires balancing the trade-off between pre-existing qualities that are gained and pre-existing qualities that are lost (and a trade-off always exists), and whether it is worth or not to rebuild them in the new format.
What’s next? In my opinion, identify the “usual” tricks through which one can implement in one data linearization format the features that are typical of another, and understand if and when these tricks have been properly implemented, and when some or more qualities have been left out. It is an interesting exercise.
Biography
Fabio Vitali is full professor in computer science at the University of Bologna (Italy), where he teaches Web Technologies and User Experience Design. He has been working on documents for many years, especially scholarly, legal and literary documents, paying attention to issues such as versioning, linking, displaying and structuring. He has been involved in the design of XML Schema 1.1, is author of Akoma Ntoso (the OASIS standard for XML representation of legislative documents), and does not like those that cannot distinguish between a document and its semantics.
Domenico Fiormonte | A response
Digital languages and instruments are not only powerful tools for simplifying and enhancing the work of humanists and social scientists, they also create new cultural representations and self-representations that transform both the epistemology and the practice of research. In my response I will focus on the socio-cultural and geopolitical implications of these representations. In particular, I will show examples of how code and encodings are shaping the way we conceive and practise the work of reconstruction, conservation and representation of information structures and cultural artefacts.
Biography
Domenico Fiormonte (PhD University of Edinburgh) is currently lecturer in Sociology of Communication and Culture at the Department of Political Sciences of the University of Roma Tre. In 1996 created one of the first online resources on textual variation (www.digitalvariants.org). He has edited and co-edited a number of collections of digital humanities texts and published books and articles on digital philology, new media writing, text encoding, and cultural criticism of DH. His last publication is The Digital Humanist. A critical inquiry (Punctum 2015) with Teresa Numerico e Francesca Tomasi. His current research interests are moving towards the creation of new tools and methodologies for promoting the interdisciplinary dialogue (http://www.newhumanities.org).
Opening Keynote
Tuesday, 15 March 2016, 5 pm
introduced by Manfred Thaller
Claire Clivaz | Multimodal Literacies and Continuous Data Publishing: Ambiguous Challenges For the Editorial Competences
Humanities is today challenged in many ways: financial threats, quest of identity, digitalization, etc. The critical edition, born in Modernity, is a traditional milestone of Humanities, and is deeply transformed by the digital writing material. Several scholars and meetings – such as the 2015 DIXIT workshop «Digital scholarly editions. Data vs Presentation?» – are regularly inquiring about what could «fundamentally» belong to the concept of edition, and what can be transformed in this field of competences, without loosing its identity markers. In this conference, I will consider this question by looking at two specific issues. First, the multimodal literacies: Humanities are producing more and more multimodal knowledge, with sound, images, texts. Does the critical edition still have its place in this new world? Secondly, if Humanities research is going in the direction of a continuous data publishing mode, will the critical edition, with its long temporality, still have its place? Both questions will be considered with concrete projects, such as the etalks (etalks.vital-it.ch), the Arabic New Testament manuscripts (tarsian.vital-it.ch), or the new journal for data publication in Life Sciences, Sciencematters (sciencematters.io).
Biography
Claire Clivaz is Head of Digital Enhanced Learning at the Swiss Institute of Bioinformatics (Lausanne). She leads her researches in an interdisciplinary way, at the crossroad of New Testament and the digital transformations of knowledge, as her bibliography shows (https://isb-sib.academia.edu/ClaireClivaz/). She leads the development of the etalks, a multimedia publication tool (etalk.vital-it.ch), as well as a Swiss National Fund on the Arabic manuscripts of Pauline letters (wp.unil.ch/nt-arabe/) and participates with six other European partners to a strategic partenariat ERASMUS+ in Digital Humanities (dariah.eu/teach). She is a member of several scientific committees (ADHO steering committee, EADH steering committee, IGNTP, Humanistica, etc.) and editorial boards (NTS, Digital Religion de Gruyter, etc.). She is co-leading a series with David Hamidovic by Brill «Digital Biblical Studies», and research groups in DH (SBL, EABS).
Papers
Critical Editing I
Wednesday, 16 March 2016, 9 – 11 am
Chair: Franz Fischer
Andreas Speer | Blind Spots of Digital Editions: The Case of Huge Text Corpora in Philosophy, Theology and the History of Sciences
Mehdy Sedaghat Payam | Digital Editions and Materiality: A Media-specific Analysis of the First and the Last Edition of Michael Joyce’s Afternoon
Raffaella Afferni / Alice Borgna / Maurizio Lana / Paolo Monella / Timothy Tambassi | “… But What Should I Put in a Digital Apparatus?” A Not-So-Obvious Choice: New Types of Digital Scholarly Editions
Andreas Speer | Blind Spots of Digital Editions: The Case of Huge Text Corpora in Philosophy, Theology and the History of Sciences | Slides
This paper is concerned with a specific genre of critical editions, which has not been properly in the focus of digital editions yet, because they mainly depart from models stemming from diplomatic editions or from new philology dealing with singular objects of limited size.
This paper focuses on huge text corpora in the field of philosophy, theology and the history of sciences – huge in size as well as with regard to their transmission. Think, e.g. of the Corpus Aristotelicum and its ample commentary tradition crossing centuries, languages, cultures and various modes of transmission; think of the most influential theological dogmatics, Peter Lombard’s Sentences, which became subject of a theological discourse sustaining over centuries, whose witnesses are uncountable and varying to a very high degree.
Even a singular text, which may comprise 80-100 folio pages in double columns transmitted in more than 200 manuscripts over three centuries, followed by a dozen early printed books, brings about a substantial challenge for digital methods and concepts of digital editions. Currently, the printed critical edition seems to be the most appropriate model and benchmark for all attempts to apply digital methods to this ample field of textual transmission. In fact, we have seen brilliant new editions over the last 2-3 decades, which raise edition philology to a new level, but are independent and often totally disconnected from digital philology.
This paper deals with the question of why huge text corpora seem to be a blind spot in the field of digital editions and what the methodological and conceptual challenges for computer philology are in becoming part of this highly innovative development.
Biography
Andreas Speer is the coordinator of DiXiT. He is full professor of philosophy and director of the Thomas-Institut of the University of Cologne, Research and Graduate Dean of the Faculty of Arts and Humanities, Director of the a.r.t.e.s. Graduate School for the Humanities Cologne and Speaker of the Cologne Center for eHumanities (CCeH). He is member of the North Rhine-Westphalian Academy of Sciences, Humanities and the Arts and member of the European Academy of Sciences (EURASC). Among his research projects are critical editions on Averroes (Ibn Rušd) and Durandus of St. Pourçain, and digital platforms as the Digital Averroes Research Environment (DARE) and the Schedula (diversarum artium)-Portal.
Mehdy Sedaghat Payam | Digital Editions and Materiality: A Media-specific Analysis of the First and the Last Edition of Michael Joyce’s Afternoon
In this paper, the early development of hypertext fiction will be approached from the perspective of the materiality of the digital text, with the purpose of demonstrating the extent to which the materiality of the digital medium has affected editing Michael Joyce’s Afternoon, which as the first work of hypertext fiction is arguably the most discussed work of early 1990s. Writing a novel in the new medium and presenting it as a work of fiction surely must have required a significant amount of (pre)meditation about narrative, new medium and the way its materiality should or should not play a significant part in the narrative, and this is what Joyce confesses to have done during the preceding years of writing Afternoon. The main reason which this novel has been chosen for this research is that Afternoon in various ways reveals how it changes when its material support as well as its reading and writing software, Storyspace, go through various updates. Those updates practically make a floppy diskette designed to be read through Storyspace 1.0 on a Mac LC, unreadable on an iMac with Storyspace 1.3.0. The stand-alone feature of the works of hypertext fiction means that their material support needs to be updated anytime that a new technology or the upgrades to the previous ones change the electronic media ecology. This has already happened once when Storyspace 1 was upgraded to Storyspace 2, which according to its developer made it a completely new computing environment. The current Storyspace available at the website of Eastgate System (late 2015) is Storyspace 2.5 for Mac OS X, and Storyspace 2.0 for Windows. As both Kirschenbaum and Harpold have demonstrated, there are several Afternoons. During the last twenty years the medium of the computer and its operating systems were developed further and further by their manufacturing companies. This made Joyce (and his publisher) develop Afternoon and edited it for the new platforms. For the contemporary reader in late 2015, apart from the web ported version only the sixth edition (for both Mac and Windows users) is commercially available, and the previous editions are already collectors’ items. This research analyzes the first commercial edition of the novel and the sixth edition to show how and in what ways this novel has been modified for different platforms and operating systems.
Biography
Mehdy Sedaghat Payam received his Ph.D. in English Literature from Victoria University of Wellington in New Zealand in 2014. In his Ph.D. thesis he explored the mutual effects of print and electronic textuality in works of experimental and digital fiction. His main area of interest is digital humanities and how this intersection of digital technology and humanities can push the boundaries of research in humanities in general and literature in particular. He is recently employed by SAMT Organization for Research in Humanities and he aims to promote digital research and teaching in all areas of humanities and introduce digital humanities to a wider academic audience in Iran through this organization. He is also a published novelist and he published his first novel, Secret of Silence or Hamlet According to Shakespeare’s Sister in Persian in 2009.
Raffaella Afferni / Alice Borgna / Maurizio Lana / Paolo Monella / Timothy Tambassi | “… But What Should I Put in a Digital Apparatus?” A Not-So-Obvious Choice: New Types of Digital Scholarly Editions | Slides
We propose to develop / expand the concept of “digital edition of a text”. The specific value of a digital edition is not only in the digital form of representation of textual information: dynamic rather than static, resulting in better visual or practical usability, but it mainly lays in the ability to work with computational methods on the text and on the information it conveys. Therefore the digital edition of a text should aim to provide adequate data and functionality to further forms of processing.
Hence the idea that the “digital scholarly edition” until now often identified with the “digital critical edition”, can also take other forms focused on other types of ‘scholarly research’: from the geographical knowledge contained in the text, to the historical knowledge (time and events) often inextricably linked with the prosopography, and much more. If the digital critical edition is a type of digital scholarly edition containing an apparatus that analyzes and describes the state of the text in the witnesses, then we can conceive e.g.
- the digital scholarly geographical edition of a work – whose apparatus contains an analytical description of the geographical knowledge contained in the placenames;
- the digital critical geographical edition whose geographical apparatus is layered over a base critical edition:
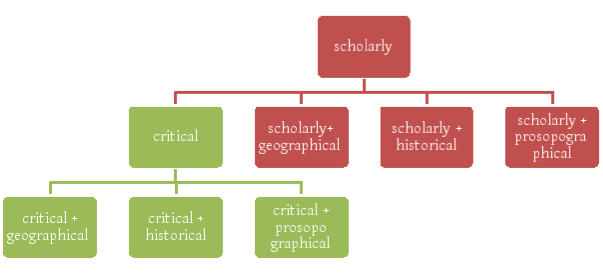
The knowledge contained in the text must be expressed in a highly formal manner – the same way that the critical apparatus is a highly formal device – by means of an ontology. The ontology both from a philosophical or a computer science point of view is a structure aimed to analyse and describe the categorical hierarchy of a specific domain, analysing its basic constituents (entities like objects, events, processes, etc.), the properties characterizing them and the relationships which correlate them. The resulting (structural) representation of knowledge allows to resolve conceptual or terminological inconsistencies, providing a dictionary of terms formulated in a canonical syntax and with commonly accepted definitions. It also provides a lexical or taxonomic framework for the representation of knowledge, shared by different communities of information systems that can range across several domains.
From a scholarly point of view we can also add that digital critical editions of classical works whose textual tradition is made of many witnesses are still very rare. The ancient literatures scholars usually ask to the digital no more than authoritative collections of texts (TLG, PHI, and online digital libraries). So the opportunity to enrich the digital text with variants (especially from a new collation of manuscripts) has known little practical application. The peculiar nature of textual variance in classical texts, where the discarded lesson is a mistake to recognize and remove, contributes to this closure face to the opportunities of the digital. Consequently a digital critical edition aimed to include a bigger number of variants – that is ‘errors’ – than in printed format is unsustainable in terms of cost / benefit evaluation. Thus a new space for reflection opens, no longer linked to the form (that is to the textual tradition) but to the content of the text formally analysed in the apparatus, which might be thought of as a space open to contain other, new, kinds of knowledge.
Biographies
Alice Borgna is currently a post-doctoral fellow at the University of Eastern Piedmont, where she also earned her Ph.D. in Latin Philology with a dissertation on Justin Epitoma Historiarum Philippicarum Pompei Trogi. During her PhD, she also received a specific training in Digital Humanities thanks to the collaboration with the DigilibLT project (Digital library of Late Antique Latin texts). She holds a B.A. and M.A. in Classics from University of Turin, where she also worked as a post-doctoral fellow.
Timothy Tambassi is a Honorary Research Fellow in Archival, Bibliographical and Library Sciences at the Department of Humanistic Studies of the University of Eastern Piedmont and works on the construction of a formal ontology which gives account to the geographic knowledge expressed in the Latin Literature by some of its main authors. He earned his Ph.D. in Philosophy at the University of Verona with a dissertation entitled ìThe Riddle of Reality: E.J. Loweís Metaphysics, Ontology, and Philosophy of Mindî.
Paolo Monella is a digital classicist with a PhD (2006) in Latin Literature and a former research fellow (2012) in Digital Humanities at the Accademia Nazionale dei Lincei, Rome. Since 2008, he has taught Digital Humanities at the University of Palermo as lecturer. His main research focus is on the methodology of digital scholarly editions.
Maurizio Lana is an assistant professor at Università del Piemonte Orientale where he teaches library and information science. He directs with R. Tabacco the digital library of late-Latin texts digilibLT, and directs also geolat – geography for latin literature, a research project aimed at allowing a geography-centered approach to the works of the Latin Literature. Previously his main research interests have been the history of Internet and tools for the management of knowledge, and the quantitative authorship attribution by means of mathematical methods.
Raffaella Afferni is a geographer with a PhD (2003) in Development policies and territorial management. Since 2006 she is lecturer at the Department of Humanities of University of Eastern Piedmont, where she teaches “Political and Economic Geography”. Her main research interests are tourism, cultural heritage, processes and policies for local development, migration.
Building Communities
Wednesday, 16 March 2016, 11 am – 1 pm
Chair: Misha Broughton
Monica Berti | Beyond Academia and Beyond the First World: Editing as Shared Discourse on the Human Past
Timothy L. Stinson | The Advanced Research Consortium: Federated Resources for the Production and Dissemination of Scholarly Editions
Aodhán Kelly | Digital Editing in Society: Valorization and Diverse Audiences
Monica Berti | Beyond Academia and Beyond the First World: Editing as Shared Discourse on the Human Past
Philologists of the digital age have to reassess their role as scholars, editors, and teachers. Emerging issues such as the availability of big data, transformations in scholarship production and teaching methods, the involvement of new audiences and interdisciplinarity have been extending the responsibility of philologists beyond academia and urging them to rethink their contribution to the society. The aim of this paper is to present and discuss some of the most important challenges of the new world of digital philology.
Biography
Monica Berti is a Classicist and works as an Assistant Professor at the Alexander von Humboldt Chair of Digital Humanities at the University of Leipzig, where she teaches courses in digital classics and digital philology. Her research interests are mainly focused on ancient Greece and the digital humanities and she is currently working on representing quotations and text reuses of Greek and Latin works in digital libraries. She is also leading SunoikisisDC, which is an international consortium of digital classics programs developed by the Humboldt Chair of Digital Humanities at the University of Leipzig in collaboration with the Harvard’s Center for Hellenic Studies.
Timothy L. Stinson | The Advanced Research Consortium: Federated Resources for the Production and Dissemination of Scholarly Editions
The Advanced Research Consortium (ARC) is a meta-federation of five period-specific “nodes”: the Medieval Electronic Scholarly Alliance (MESA), 18thConnect, and the Networked Infrastructure for Nineteenth-Century Electronic Scholarship (NINES) have been launched and are interoperable, while the Renaissance English Knowledgebase (REKn) and Modernist Networks (ModNets) are under development. Each node comprises a group of federated digital projects, provides peer review of digital scholarly work in a field of study, aggregates data and makes it searchable from a single portal, and offers a suite of online tools that allow users to collect, tag, and annotate digital objects. Because the nodes share metadata, standards, and software, they are interoperable, and thus ARC provides researchers with the option of searching any combination of the nodes or all of them at once. Collectively the nodes cover from c. 450 AD through the twentieth century.
Together ARC member projects currently contain almost two million digital objects, the large majority of which are digital images of books, from early medieval codices through nineteenth-century printed works and twentieth-century scholarship. We also feature a number of scholarly editions, such as the Petrus Plaoul Editiones Electronicas, the Piers Plowman Electronic Archive, and the Rossetti Archive, as well as the raw materials – in the form of digital images and transcriptions – for many other texts and objects that could be used in the creation of new scholarly editions. We work closely with editors both to advise on the creation of metadata at the outset of their projects and to peer review their scholarly editions once they are completed.
I propose to offer an introduction to ARC that will focus on those aspects of our mission that are most relevant to the creation, publication, dissemination, and sustainability of scholarly editions in digital environments. Topics to be addressed include the challenges inherent in the peer review of and credit for digital editions, the potential of large-scale aggregation sites to offer a venue for crowdsourcing of transcription and other tasks related to editing, and both technical and social practices that enhance discoverability, dissemination, and sustainability of editions. Because our members include scholarly editing projects, museums, libraries, publishers, and commercial aggregators of content, ARC provides multiple points of views into these issues.
Biography
Timothy Stinson is associate professor of English at North Carolina State University. He has published articles on the Alliterative Revival, printing history, codicology, manuscript illumination, and the application of genetic analysis to the study of medieval parchment. He is editor of the Siege of Jerusalem Electronic Archive, is co-founder and co-director of the Medieval Electronic Scholarship Alliance (MESA), and co-director of the Piers Plowman Electronic Archive. His research has received funding from the National Endowment for the Humanities, the Andrew W. Mellon Foundation, the Bibliographical Society of America, and the Council on Library and Information Resources.
Aodhán Kelly | Digital Editing in Society: Valorization and Diverse Audiences | Slides
The perceived potential to reach broader publics has been an oft-discussed topic since the earliest adoption of digital technologies for the publication of scholarly editions. A dichotomous concept of ‘audience’ has become prevalent in the field, divided into ‘scholarly’ and ‘non-scholarly’. John Lavagnino, for example, described it as ‘the problem of two audiences’ while Edward Vanhoutte has proposed an integrated dual-model of maximal and minimal editions, one aimed at each audience. This dichotomy typically renders that there are two potential outputs: the ‘scholarly edition’ aimed at scholars, and the ‘reading edition’ for a general public. But what happens beyond this, what other ways does digital editing attempt to valorise scholarly knowledge in society at large?
This paper will argue that there is, rather, a diverse spectrum of publics who possess overlapping layers of interests, competences and capacities. Not only can audiences be extremely diverse but so can the potential means that could be employed to engage them. What forms of engagement do we value and how? Are efforts constricted by limitations imposed by the academy regarding scholarly credit, by skillsets or by something else? Spin-off publications aimed at general audiences are often considered to be a form of ‘outreach’, a side-project to the scholarly edition itself but is that a healthy perspective to take on scholarship? Are we limiting our efforts geographically or should there be attempts to engage more globally diverse audiences in the manner advocated for by the Global Outlook Digital Humanities (GO::DH) research group?
By assessing user data from the field in combination with an assessment of existing digital engagement methods employed in digital editing and related disciplines, this paper will offer a state of the field in efforts to valorise scholarly knowledge with more global and diverse audiences, and attempt to suggest some potential avenues for further exploration.
Biography
Aodhán Kelly is a DiXiT fellow and PhD student based at the University of Antwerp. His research involves devising methodologies for disseminating textual cultural heritage using digital means for purposes of research, pedagogy and public engagement. He holds a masters degree in history from Maynooth University in Ireland and previously worked as a digital editor in the publishing industry in the UK.
Cultural Heritage
Wednesday, 16 March 2016, 2 – 4 pm
Chair: Martin Bloomer
Hilde Bøe | Edvard Munch’s Writings: Experiences from Digitising the Museum
Torsten Schaßan | The Influence of Cultural Heritage Institutions on Scholarly Editing in the Digital Age
Dinara Gagarina / Sergey Kornienko | Digital Editions of Russia: Provincial Periodicals for Scholarly Usage
Hilde Bøe | Edvard Munch’s Writings: Experiences from Digitising the Museum | Slides
Over the last eight years the Munch Museum has been working with its digital archive on Edvard Munch’s writings and correspondence. The digital archive was launched in 2011, but the work is still on-going. 3/5 of Munch’s own writings have been published online as well as half of the correspondence addressed to Munch, and a selection of about 1100 pages of his notes on art and his literary sketches have been translated in to English and published at emunch.no.
Munch’s writings have been a somewhat hidden treasure and were little known. They have been registered as museum objects, i.e. with little thought of what they are or what belongs together from a textual perspective, and although they have been transcribed, not much research has been done. Being a private archive of notes (of “all kinds”), literary sketches, prose poems, letters and letter drafts they are often hard to categorise precisely as they lack proper genre features, dates etc. Aside from the sent letters, most of the texts are in an unfinished state of some kind and there are also often several versions.
Much better known of course are Munch’s artworks, be it his paintings or the graphical prints. The collection also comprises some 7000 drawings as well as furniture, family letters, artist’s equipment (1000 paint tubes!) to mention some. In the coming years the museum will be working on creating an online presentation of all objects in its collection. Many of them are related to each other since Munch often worked on the same motifs in whatever media he chose.
In my talk, I will reflect upon experiences we have had while working with the writings, challenges we have met, and upon the work ahead of us; what can we hope to achieve? What should we aim for?
Biography
Hilde Bøe is the scholarly and technical editor of Edvard Munch’s Writings and Digital Collection Manager at the Munch Museum. She is the administrator of the Museum’s collection database and in charge of the planning of the museum’s coming digital collection presentation. Bøe has a Master in Nordic Literatures and Languages and has worked in digital humanities related jobs since her graduation.
Torsten Schaßan | The Influence of Cultural Heritage Institutions on Scholarly Editing in the Digital Age | Slides
In the digital age academia is still searching for standards for digital editions. Agreements on core functionalities of digital editions, common tools to exploit the data, prefered access ways, or the balance between standardisation and ambition for singularity and recognition yet have to found. Even the common sense that digital editions are best encoded using the TEI might not be without problems: one TEI document does not necessarily conform to other TEI-encoded documents.
Cultural heritage institutions -especially libraries- become responsible for storing and maintaining of digital materials such as digital editions. Their policies about maintenance of data and functionalities will influence the production of digital editions. Additionally, libraries will serve as publishing agencies and they will influence all the decisions as answers to the questions mentioned above.
This paper will explore the fields where cultural heritage institutions -namely libraries- influence the encoding, the functionalities, and the publication of digital editions and present some of the answers to some of the questions as discussed in libraries.
Biography
Torsten Schaßan is member of the Manuscripts and Special Collections Department of the Herzog August Bibliothek Wolfenbüttel. He is in charge to supervise the digital editions published in the Wolfenbüttel digital library. He is also member of the Institute for Documentology and Scholarly Editing and an active member of the TEI.
Dinara Gagarina / Sergey Kornienko | Digital Editions of Russia: Provincial Periodicals for Scholarly Usage | Slides
Provincial periodicals are widely used in regional studies. At the same time, collection of newspapers and their parts are often scattered in different museums, libraries and archives that hinders access of researchers to them and creates a completeness problem of the information source. Digital editions and information systems provide the solution of this problem as well as preservation of historical source.
Laboratory of historical and political Information science of Perm University (Russia) in cooperation with Perm region museum have implemented a series of projects based on provincial newspapers of 19th – beginning of 20th centuries. We select collections chronologically or thematically, digitize them and create information systems, which preserve and provide wide access to cultural heritage data as well as allow their scholarly usage.
Information system “First World War in Perm Province Periodicals” allows preserving and organizing ten collections of newspapers into a single whole and contains more than 2.5 thousand newspapers issues published in Perm region during the First World War. The system provides free access to periodicals and the ability to use both traditional and computerized methods to study them.
Like most full-text source-oriented systems information system “First World War in Perm Province Periodicals” allows to analyse the whole collection of issues and its fragments as a single text and obtain characterizing of various stages and the dynamics of publication that are not available in the case of using traditional methods. By means of different types of database queries and search tools, we can obtain quantitative characteristics, samples for various themes and specific items of publications. The implementation of these types of queries permits to determine the most common types and genres, subject focus of publications and their relation, generate text fragments and interpretation of the results in terms of the completeness and nature of the information source.
The main objects of the information system model are newspaper, issue and publication.
Newspaper’s metadata includes name, period of publication, editor, archeographic description. For each newspaper, hyperactive list of available numbers can be viewed.
Issue’s metadata includes newspaper, number, date. Each issue is presented page by page in PDF format (text below the image) that helps preserving the content of newspapers as much as possible and provides accessibility to researchers. Recognized text layer enables contextual information search, use computerized content analysis along with traditional methods. Issue’s page displays the list of his publications on military theme.
Publication’s metadata includes title, newspaper, date, issue number, pages, author, rubric, type of publication, mentioned persons, mentioned place-names, keywords and text.
Information system “First World War in Perm Province Periodicals” is available on http://permnewspapers.ru.
Biographies
Sergey Kornienko, Professor, Dr. of Historical Science, Perm State University, Department of Modern Russian History, Laboratory of Historical and Politological Information Science. Scientific interests: Russian history, Digital History, Digital Humanities, source study, historiography, history methodology.
Dinara Gagarina, Associate Professor, PhD (Candidate of Pedagogical Science), Perm State University, Department of Information Technologies. Scientific interests: IT and math in history, Digital History, Digital Humanities, e-learning, information systems for scholar use.
Museum Lecture
Wednesday, 16 March 2016, 7 pm
Kolumba Museum
Helene Hahn | OpenGLAM & Civic Tech: Working with Communities|Slides
Reception & Tour
What kinds of creative possibilities can be uncovered if digitized cultural data is made freely available and reusable? Coding da Vinci gives German cultural heritage institutions the possibility to cooperate with designers, software and game developers, to foster and share their expertise in order to realize digital projects for the cultural sphere as well as for the public in general. Through this productive cooperation the institutions obtain new perspectives on their digital collections, and the visitors experience entirely new forms of interaction with cultural artifacts.
Biography
Helene Hahn is working on different aspects of the knowledge society and the digital world. She devoted herself to the protection of digital human rights and civic participation made possible by the use of new technologies and open data.
At the Open Knowledge Foundation Germany she works as a project lead and is responsible among others for the cultural data hackathon “Coding da Vinci”. She studied cultural sciences and economics in Germany and abroad.
Social Editing & Funding
Thursday, 17 March 2016, 9 – 11 am
Chair: Tessa Gengnagel
Ray Siemens | The Social Edition in the Context of Open Social Scholarship
Till Grallert | The Journal al-Muqtabas Between Shamela.ws, HathiTrust, and GitHub: Producing Open, Collaborative, and Fully Referencable Digital Editions of Early Arabic Periodicals — With Almost No Funds
Misha Broughton | Crowd-Funding the Digital Scholarly Edition: What We Can Learn From Webcomics, Tip Jars, and a Bowl of Potato Salad
Ray Siemens | The Social Edition in the Context of Open Social Scholarship
Scholarly editing is anything but static, perhaps especially so in the digital realm where we’ve moved quickly since the late 1980s in our conceptions of electronic scholarly editing from dynamic text, to hypertextual edition, to dynamic edition, and beyond. The concept of social scholarly editing (and the social edition) represents a further extension of movement in this vein, building on scholarly editing practices of the past and present, and adding to them elements of new and emerging social media. This paper considers the social edition in this framework, and reflects further on its place more generally in the context of open social scholarship.
Biography
Ray Siemens (U Victoria, Canada; http://web.uvic.ca/~siemens/) is Distinguished Professor in the Faculty of Humanities at the University of Victoria, in English and Computer Science, and past Canada Research Chair in Humanities Computing (2004-15). He is founding editor of the electronic scholarly journal Early Modern Literary Studies, and his publications include, among others, Blackwell’s Companion to Digital Humanities (with Schreibman and Unsworth), Blackwell’s Companion to Digital Literary Studies (with Schreibman), A Social Edition of the Devonshire MS (MRTS/Iter, and Wikibooks), and Literary Studies in the Digital Age (MLA, with Price). He directs the Implementing New Knowledge Environments project, the Digital Humanities Summer Institute, and the Electronic Textual Cultures Lab, recently serving also as Vice President / Director of the Canadian Federation of the Humanities and Social Sciences for Research Dissemination, Chair of the MLA Committee on Scholarly Editions, and Chair of the international Alliance of Digital Humanities Organisations.
Till Grallert | The Journal al-Muqtabas Between Shamela.ws, HathiTrust, and GitHub: Producing Open, Collaborative, and Fully Referencable Digital Editions of Early Arabic Periodicals — With Almost No Funds | Slides
In the context of the current onslaught cultural artifacts in the Middle East face from the iconoclasts of the Islamic State, from the institutional neglect of states and elites, and from poverty and war, digital preservation efforts promise some relief as well as potential counter narratives. They might also be the only resolve for future education and rebuilding efforts once the wars in Syria, Iraq or Yemen come to an end.
Early Arabic periodicals, such as al-Jinān (Beirut, 1876–86), al-Muqtaṭaf (Beirut and Cairo, 1876–1952), al-Muqtabas (Cairo and Damascus, 1906–16) or al-Manār (Cairo, 1898–1941) are at the core of the Arabic renaissance (al-nahḍa), Arab nationalism, and the Islamic reform movement. Due to the state of Arabic OCR and the particular difficulties of low-quality fonts, inks, and paper employed at the turn of the twentieth century, they can only be digitised by human transcription.Yet despite of their cultural significance funds for transcribing the tens to hundreds of thousands of pages of an average periodical are simply not available. Consequently, we still have not a single digital scholarly edition of any of these journals. But some of the best-funded scanning projects, such as Hathitrust, produced digital imagery of numerous Arabic periodicals, while gray online-libraries of Arabic literature, namely shamela.ws, provide access to a vast body of Arabic texts including transcriptions of unknown provenance, editorial principals, and quality for some of the mentioned periodicals. In addition, these gray “editions” lack information linking the digital representation to material originals, namely bibliographic meta-data and page breaks, which makes them almost impossible to employ for scholarly research.
With the GitHub-hosted TEI edition of al-Muqtabas we want to show that through re-purposing available and well-established open software and by bridging the gap between immensely popular, but non-academic (and, at least under US copyright laws, occasionally illegal) online libraries of volunteers and academic scanning efforts as well as editorial expertise, one can produce scholarly editions that remedy the short-comings of either world with very small funds: We use digital texts fromshamela.ws, transform them into TEI XML, add light structural mark-up for articles, sections, authors, and bibliographic metadata, and link them to facsimiles provided through HathiTrust (in the process of which we also make first corrections to the transcription). The digital edition (TEI XML and a basic web display) is then hosted as a GitHub repository with a CC BY-SA 4.0 licence.
By linking images to the digital text, every reader can validate the quality of the transcription against the original, thus overcoming the greatest limitation of crowd-sourced or gray transcriptions and the main source of disciplinary contempt among historians and scholars of the Middle East. Improvements of the transcription and mark-up can be crowd-sourced with clear attribution of authorship and version control using .git and GitHub’s core functionality. Editions are referencable down to the word level for scholarly citations, annotation layers, as well as web-applications through a documented URI scheme. The web-display is implemented through a customised adaptation of the TEI Boilerplate XSLT stylesheets; it can be downloaded, distributed and run locally without any internet connection—a necessity for societies outside the global North. Finally, by sharing all our code (mostly XSLT) in addition to the XML files, we hope to facilitate similar projects and digital editions of further periodicals.
Biography
Till Grallert (Orient-Institut Beirut) works on a genealogy of urban food riots in Ottoman Bilād al-Shām between the 18th and 20th centuries. He completed his PhD on the production of public places and public space in late Ottoman Damascus in 2014. He has a long-standing interest in intellectual and semantic histories, media history and the digital humanities.
Misha Broughton | Crowd-Funding the Digital Scholarly Edition: What We Can Learn From Webcomics, Tip Jars, and a Bowl of Potato Salad | Slides
The internet is rapidly changing the way in which content creators interact with the consumers and supporters of their work. Besides the obvious boon of a cheap publication platform, the internet offers these creators an avenue to appeal directly to their fan-bases for support, both economic and creative. And the response – in certain cases, at least – has been overwhelming. Young twenty-somethings in London are making millions of pounds recording and distributing the results of their Primark shopping trips on YouTube. Comic artists are finding that their fans are not only willing to pay them for the cartoons they once drew as a hobby, but are also willing to help them organize and publish that work. In some instances, those fans are even willing to pay for the opportunity to help. Meanwhile, KickStarter continues to grow as a vehicle for supporters around the world to provide funds for small (and not so small) projects, even before a deliverable product exists.
This paper argues that what these projects offer, besides their obvious entertainment value, is a sense of participation: that the incentive for contribution – either of effort or of cash – is less the product the supporters might receive, and more the ability to claim a small measure of personal ownership of the project itself. But do scholarly editing projects hold enough of a share of public attention to turn this desire for participation to their benefit? This paper argues that some projects very well might. But, more importantly, what are the possible risks and rewards of doing so?
Biography
Misha Broughton is a doctoral student and a DiXiT Early Stage Research Fellow at the University of Cologne, studying “Mass Digitization data for scholarly research and digital editions.” His research interests include theories of text encoding, social editing, and the interaction of textual scholarship and scholarly editing with the larger social world of the internet.
Publishing
Thursday, 17 March 2016, 11 am – 1 pm
Chair: Anna Cappellotto
Michael Pidd | Scholarly Digital Editing by Machines
Anna-Maria Sichani | Beyond Open Access: (Re)use, Impact and the Ethos of Openness in Digital Editing
Alexander Czmiel | Sustainable Publishing: Standardization Possibilities For Digital Scholarly Edition Technology
Michael Pidd | Scholarly Digital Editing by Machines
The very suggestion that scholarly editing can be undertaken by machines is probably an anathema for the majority of academics. Price declares: “Mere digitizing produces information; in contrast, scholarly editing produces knowledge” (2008). The problem with Price’s view is that computers do more than simply digitise. Machines have always assisted with the process of scholarly editing; whether it be undertaking large decision-making tasks – at scale – because the answers can be deduced by computational logic, or presenting complex evidence in a way that makes it easier for the editor to take a critical view.
However, we are now asking machines to undertake more ‘critical thinking’ tasks than ever before (and sometimes we even ask the general public to do it!) as our desire to access large bodies of primary sources increases but the funds to create them meticulously decreases. On some projects the scholarly editor is now reduced to performing a critical review of work that is the product of algorithms. The end result is probably unsurprising and reassuring: the more we ask machines to do our thinking for us, the less accurate our editions become, whether it be the machine’s representation of the primary source as written evidence (e.g. transcription) or its interpretation of the content (e.g. semantic mark-up). But is it as simple as this? Are machine-driven editions really less accurate than those that are created solely by humans? Machine learning techniques are now being used to generate convincing journalism in domains such as sport and economics, but the significance of automation in areas of academic writing such as scholarly editing is yet to be fully appreciated or understood.
In this talk I will explore how computational processes have become central to achieving the kinds of scholarly critical editions that we require today — whether it be semantic mark-up, variant analysis, record linkage, concept modelling, automatic summarisation or knowledge modelling using ontologies and visualisations. Through the process of developing and implementing algorithms that understand or make sense of our data, I will argue that scholarly editing has become a form of engineering: encoding the critical thinking of humanities experts into the decision-making processes of computer algorithms. My talk will draw on a number of digital editing projects from HRI Digital at The University of Sheffield as case studies, showing the successes and failures that can occur when we allow machines to get too close to our editions. Case studies will include: Old Bailey Online, London Lives, Intoxicants in Late Modernity, Linguistic DNA, Digital Panopticon, Foxe’s Book of Martyrs, and The Canterbury Tales (http://hridigital.shef.ac.uk).
Biography
Michael Pidd is Director of HRI Digital, the Digital Humanities team at the University of Sheffield’s Humanities Research Institute. Michael has over 20 years experience in developing, managing and delivering technology-based research projects in the arts and humanities. His team provides technology services that support colleagues throughout UK Higher Education on funded research projects, such as: digitisation; programming; the specification, design and build of online research resources; data management; project management; data preservation; and the hosting and maintenance of online resources over the long term. HRI Digital has particular specialism in Natural Language Processing techniques, text data mining, data visualisation, 3D visualisation and linked data.
Anna-Maria Sichani | Beyond Open Access: (Re)use, Impact and the Ethos of Openness in Digital Editing | Slides
In recent years, concepts such as Open Access, Open Data, Open Source and other open scholarship practices have exerted an increasingly prevalent influence on the digital information environment in which scholarly content is created and disseminated. Originating from academics and libraries calling for “free immediate access to, and unrestricted reuse” (PLOS, n.d.) of scholarly research, and strategically reinforced by the rhetoric of Open Definition – celebrating content that is “freely used, modified, and shared with anyone for any purpose” (Open Definition, n.d.) –, open access agenda currently starts to inform also the practice of many cultural and heritage institutions on opening up access to their digitised primary content through the OpenGlam initiative (Terras 2015). Notions of value, impact, open access and sustainability remain entwined within this virtuous cycle of open content and data, especially in the Humanities. Initiatives ranging from mapping the effect of Open Access on citation impact within academia (Opcit) to funding agencies calling on projects to demonstrate the impact of their openly available content in order “to quantify the value of the investment on their creation”, manifest an ever-growing research interest in the (re)use and impact assessment of open digital content, foregrounding scholarly endeavours that fortify the creation of knowledge and its communication beyond open access.
Digital scholarly editing has long established itself as a field constantly engaged in the perpetual renewal of models geared towards critically remediating and communicating texts and documents. Today, it attempts to situate these concepts and practices within a flourishing culture of open digital content and scholarship. Though the number of publicly accessible digital editions remains on the increase, limitations in adopting an Open Access agenda in digital editing persist. Aside from legal, economic, or administrative reasons behind licensing complications, current discussions conclude that the “page paradigm” remains a crucial hindrance; its inheritance is still so strong in our scholarly culture that we remain “zoned to print”, thus tending to create and use digital editions as end products handed over to the user “to be seen and not touched”.
On what level and for what reasons are digital editing projects offering not only the right to access but also to (re)use, integrate and remodule their underlying data (high-resolution digital facsimiles, rich metadata, transcription and XML encodings, scripts, style sheets etc.) into new scholarship? How can traces of (re)use and the impact of a digital editing project be used to celebrate Open Access while also ensuring scholarly value and its sustainability? This paper will critically engage with digital editing and Open Access through the lens of scholarly impact and value creation, by mapping the current practices employed, conducting an impact assessment of exemplary digital editing projects through quantitative approaches (log analysis, webometrics) and finally discussing benefits and models for adopting an Open Access ethos in digital editing.
Biography
Anna-Maria Sichani is a Marie Skłowdowska-Curie Fellow in the Digital Scholarly Editions Initial Training (DiXiT) Network. She is based at Huygens ING researching “Long-term business models in dissemination and publishing of digital editions”. Her research interests include digital scholarly editing and publishing, cultural and social aspects of transitional media changes, scholarly communication, Modern Greek literary studies, research infrastructures and digital pedagogy.
Alexander Czmiel | Sustainable Publishing: Standardization Possibilities For Digital Scholarly Edition Technology
After decades of building digital resources for humanities research, such as Digital Scholarly Editions (DSE), and making them available to researchers and the broader public, we are at the point where many of these resources can be connected to one another and are more and more accepted by the scholarly community. However, we also experience the challenge to maintain all the various Digital Scholarly Editions which were built on a diverse base of different technologies. This is especially complex as Digital Scholarly Editions are “living” objects. On the one hand, that means that the content can be extended and refined continuously. Hence they are never finished. On the other hand, the technological basis must be kept alive, secure and running. Those two processes can be summarized under the term “data curation”.
If we assume that a Digital Scholarly Edition not only consists of the marked up texts, the XML documents, but also of another layer on top of the XML documents, the functionality layer – all the interactive parts, the visualizations and the different views on the texts, indexes or other research material, such as images or audio documents – it is obvious that data curation can become an unlimited complex task. This functionality layer provides an enormous additional benefit to the texts. A Digital Scholarly Edition can be seen as a tool which is used to analyze the XML documents, thus as part in the research process which must be preserved to reproduce research results which often can not be achieved without the functionality layer.
To make a comprehensive data curation possible a technological publishing concept which uses standardized components is needed. Such a concept can consist of standards for a formal project documentation, a description of the used technologies and the provided interfaces, a design paradigm for typical user interaction tasks and many more. Standards on the data- and metadata-layer are broadly accepted and in use – one example are the Guidelines of the Text Encoding Initiative (TEI – http://www.tei-c.org) – but they are still missing for the functionality layer.
A possible next step would be to package those XML documents together with the source code of the functionality layer in a standardized self descriptive format. An option for this task could be the EXPath Packaging System (http://expath.org/modules/pkg/), which works well for XML-based Digital Scholarly Editions and is widely used by digital humanities projects which are published via exist-db (http://exist-db.org). The main purpose of such a packaging system is not connectivity or interoperability rather than maintenance and data curation. The packaging system can be extended gradually to a technological publishing format which incorporates all aforementioned aspects.
It is difficult to find a standardized, generic approach in the world of Digital Scholarly Editions as every project encounters a different set of problems and a different set of uses. Thus it is important as developers to not make too many assumptions about the nature of a project and further the development of a technological publishing standard in continuous exchange with the scholarly community and in very small steps which take into account the diversity across the humanities.
Biography
Alexander Czmiel is working as researcher in the field of Digital Humanities at the TELOTA working group of the Berlin-Brandenburg Academy of Sciences and Humanities. He has been developing Digital Scholarly Editions with XML, XML-databases and TEI, and other kinds of digital resources for the humanities for over 15 years. Furthermore he is member of the Institute of Documentology and Scholarly Editing (IDE), a network of researchers working on the application of digital methods on historical documents, which offers workshops and schools twice a year in which he teaches also TEI and X-technologies.
Licenses
Thursday, 17 March 2016, 2 – 4 pm
Chair: Gioele Barabucci
Walter Scholger | Intellectual Property Rights vs. Freedom of Research: Tripping Stones in International IPR Law
Wout Dillen | Editing Copyrighted Materials: On Sharing What You Can
Merisa Martinez / Melissa Terras | Orphan Works Databases and Memory Institutions: A Critical Review of Current Legislation
Walter Scholger | Intellectual Property Rights vs. Freedom of Research: Tripping Stones in International IPR Law
The contribution will address some of the most common and frequent needs and obstacles regarding legal issues in current digital scholarship (e.g. ownership of digital copies, electronic provision of source material) and demonstrate some of the consequent misconceptions, restrictions and legal traps which result from the lack of legal certainty due to the heterogeneous international legal situation regarding IPR and ancillary copyright. Examples from continental European legislation will be compared to the Anglo-American concepts of Fair Use and Fair Dealing. In conclusion, an attempt will be made to define a possible best practice based on the common denominators found in the differing legal system, international treaties and the EC Digital Agenda for Europe, as well as alternative publication and licensing strategies (e.g. Creative Commons licenses and Open Access).
Biography
Walter Scholger studied History and Applied Cultural Sciences in Graz (AT) and Maynooth (IE). Having nurtured an interest at the intersection of digital methods, information technology and humanities research even during his studies, he was appointed as the assistant director of the Centre for Information Modeling – Austrian Centre for Digital Humanities the University of Graz in 2008. Besides dealing with administrative issues, project management and the coordination of the Centre’s teaching activities, he is working on DH curricula development and issues of digital (humanities) pedagogy. His research focus lies on issues of copyright and intellectual property rights related to research and cultural heritage, as well as alternative ways of publication and licensing in the academic field.
Wout Dillen | Editing Copyrighted Materials: On Sharing What You Can| Slides
One of the great advantages the digital medium has to offer the field of scholarly editing is that it makes its products much easier to distribute. No longer bound to a shelf, the Digital Scholarly Edition has the potential to reach a much wider audience than a printed edition could. To a certain extent, however, the nature of the materials textual scholars are working with dictates the perimeters within which this dissemination can take place. When working with modern manuscripts, for instance, copyright restrictions may limit the extent to which a project can distribute its resources. In an academic climate where open access is not only becoming a standard, but in some cases even a requirement for receiving funding, such limitations may be perceived as problematic. In this paper, I will argue that even within the boundaries of copyright restrictions there can still be room to produce and distribute the results of textual scholarship. I will do so by zooming in on the way in which different Digital Scholarly Editions of copyrighted materials deal with this issue, more specifically on those of the Beckett Digital Manuscript Project (www.beckettarchive.org), and Woolf Online (www.woolfonline.com). To conclude, I will look into other strategies that may be used to share as much research data as we are allowed to, e.g. by sharing metadata and ancillary data, or by using the fair use doctrine to circumvent the problem.
Biography
Wout Dillen is currently working at the University of Antwerp (Belgium) as a postdoctoral researcher for DARIAH-BE. His doctoral thesis was titled Digital Scholarly Editing for the Genetic Orientation: The Making of a Genetic Digital Edition of Samuel Beckett’s Works, and was part of the ERC project ‘Creative Undoing and Textual Scholarship (CUTS)’, supervised by prof. dr. Dirk Van Hulle. For this project, he also developed an online Lexicon of Scholarly Editing (http://uahost.uantwerpen.be/lse) that was initiated by Dirk Van Hulle. He is a board member of the European Society for Textual Scholarship (ESTS), and part of the Steering Committee of DH Benelux. In April 2016, he will start working at the University of Borås (Sweden) as part of the DiXiT Marie Curie Initial Training Network.
Merisa Martinez / Melissa Terras | Orphan Works Databases and Memory Institutions: A Critical Review of Current Legislation | Slides
In 2014, legislation was enacted in the UK and the EU to introduce the Orphan Works Register and the EU Orphan Works Database, respectively. Orphan works “are those whose copyright owners are unknown and unable to be found after diligent search by would-be reproducers.” These databases allow cultural heritage institutions (CHIs) to register works for review in order to obtain short-term licenses. The enactment of this legislation, with two swiftly introduced and problematic databases, has been contested by CHIs, to whom this had previously been touted as a relief from the nebulous “risk-management” complication of publishing orphan works in digital formats without clear policies. Post-enactment, rather than alleviating problems, these databases have resulted in a highly bureaucratic, expensive and time-consuming system that could negatively affect collection policies, funding structures, and relationships between CHIs and scholarly editing projects. Indeed, it is estimated that 5-10% of print materials in CHIs throughout Europe and the UK could be considered orphan works. The British Library alone estimates that over 40% of its printed works are orphans. This problem extends beyond CHIs, and directly affects scholarly editors: if would-be rights-holders make claims on orphan images of texts supplied to scholarly edition projects by libraries, those images must then be temporarily (or perhaps permanently) taken down, registered, and paid for (more than once, and providing the license is granted by the governing body). This cost in time and finances may be beyond both scholarly editing projects and CHIs. Therefore this legislation’s current manifestation may have a significant effect on the type and extent of materials that will be uploaded and made into digital scholarly editions.
This paper discusses results of a survey sent to CHIs in the UK and EU that have either tried to secure licenses or taken a risk-management approach to their collections. The survey covers questions on implementation of the legislation as it relates to their specific institutions, as well as efficacy of documentation and user guidelines on the registry sites, user interfaces, and results of the application for licenses (where relevant). The paper further presents analysis of responses to structured interviews with heavy users as well as administrators of the databases, in order to better understand how implementation of this legislation is affecting CHIs.
Our results indicate that the significance of this system for CHIs and users of their content is manifold. For example, licenses acquired in the UK are only good for the UK, meaning that any images that could be uploaded to the internet must then be applied for again using the EU database in order for those images to be legally displayed on the web in other countries, and vice versa. Presenting this work at the DiXiT conference will give context to this new system, its problems, and the impact these databases have had on CHIs and, more broadly, scholars and those who use orphan works in their digital projects.
Biographies
Merisa Martinez is a PhD Candidate at the University of Borås and a DiXiT Early Stage Research Fellow. Her PhD research explores the interdisciplinary nature of Library and Information Science and the Digital Humanities, with a particular focus on scholarly editing and cultural heritage digitization as two sites of critical transmission activities.
Melissa Terras is Director of UCL Centre for Digital Humanities, Professor of Digital Humanities in UCL Department of Information Studies, and Vice Dean of Research in UCL’s Faculty of Arts and Humanities. With a background in Classical Art History, English Literature, and Computing Science, her doctorate (Engineering, University of Oxford) examined how to use advanced information engineering technologies to interpret and read Roman texts, and her since research focuses on the use of digitisation techniques to enable research in the arts and humanities that would otherwise be impossible.
 Club Lecture
Club Lecture

Thursday, 17 March 2016, 7 pm
Stereo Wonderland
Cologne Commons Live Performance by Drehkommando Grüner Würfel
Ben Brumfield | Accidental Editors and the Crowd| Watch on Youtube | Transcript & Slides
Social digital scholarly editions have been the subject of much discussion over the last few years, with no clear conclusions emerging as to whether social editing is even possible. Meanwhile, communities disconnected from the editorial tradition have been using online tools to produce collaborative digital editions, often without even using the term “edition”.
This talk will present the history and practices of non-scholarly digital editing — editorial projects run by amateurs, or by professionals trained in unrelated fields. We will cover grass-roots efforts by genealogists, historical re-enactors, and martial arts practitioners to create editions that serve their communities’ needs. We will discuss the predicament of the “accidental editor” — the professional in charge of a crowdsourced transcription project who suddenly finds themselves fielding questions about palaeography and encoding from their volunteers without any preparation from their own academic formation. What are their practices for collaboration, for conventions, and for publication?
Biography
Ben Brumfield is an independent software developer and consultant specializing in crowdsourced transcription and digital editions. In 2005, he began developing one of the first web-based manuscript transcription systems. Released as the open-source tool FromThePage, it has since been used by libraries, museums, and educators to transcribe archaeology correspondence, military diaries, herpetology field notes, and punk rock fanzines. Ben has been writing and speaking about crowdsourced transcription technologies since 2007.
Critical Editing II
Friday, 18 March 2016, 9 – 11 am
Chair: Patrick Sahle
Charles Li | Critical Diplomatic Editing: Applying Text-critical Principles as Algorithms
Vera Faßhauer | Private Ducal Correspondences in Early Modern Germany (1546-1756)
Cristina Bignami / Elena Mucciarelli | The Language of the Objects: “Intermediality” in Medieval South India
Charles Li | Critical Diplomatic Editing: Applying Text-critical Principles as Algorithms | Slides
In recent years, text-based research in the humanities has shifted dramatically from working with critically-edited texts to diplomatically-transcribed documents. This is with good reason: both the refinement of computational techniques and growing interest in the intricacies of textual transmission have increasingly led scholars to create archives of transcribed documents in order to facilitate computer-aided textual analysis. But for scholars of an ancient text, it is still vitally important to have a critical edition, with a carefully curated apparatus to work with. This is especially evident in the context of Sanskrit texts, some of which exist in dozens, if not hundreds of manuscript witnesses, most of which are extremely corrupt. Many of these documents, when transcribed diplomatically, are simply unreadable.
But nothing prevents us from producing both a critical edition and an archive of document transcriptions that are the source of the edition; in fact, this seems like a natural solution, not only because it facilitates corpus research, but also because it makes the edition much more transparent and open. As a scholarly product, the critical edition should be, in a way, reproducible – the reader should be able to easily trace an edited passage back to its sources, noting precisely what emendations have been made. The critical apparatus has traditionally served as the repository for this information, but, crucially, some silent emendations and omissions – for example, of very common orthographic variants – are inevitably made in order to make the apparatus useful.
The “usefulness” of a critical apparatus depends both on the editor’s judgment of what to include or exclude and also on a given reader’s needs, which may or may not align with the editor’s critical principles. The challenge, then, is to make the critical apparatus flexible – to allow the reader to change the level of detail presented in the apparatus, on demand. In this paper, I will present a hypertext edition and an open-source software platform currently in development that performs automatic collation on demand and generates an apparatus for a base text and a set of variant texts, with constraints on the level of detail to be included in the apparatus that can be adjusted by the reader. These constraints are essentially the reader’s text-critical principles, expressed as parameters that guide the collation algorithm. I will consider the specific challenges and solutions of such a platform as they relate to the presentation of Sanskrit texts as well as the general scholarly aims that I hope to achieve by producing such a work.
Biography
Charles Li is currently completing his doctoral research at the University of Cambridge, where he is editing the Dravyasamuddeśa, a 5th-century Sanskrit treatise on the philosophy of language, along with a 10th-century commentary.
Vera Faßhauer | Private Ducal Correspondences in Early Modern Germany (1546-1756)
The DFG-funded project Private Ducal Correspondences in Early Modern Germany is based at the Friedrich Schiller University of Jena and the Humboldt University of Berlin. It is led by Rosemarie Lühr and carried out by Vera Faßhauer, Daniela Prutscher and Henry Seidel. By combining literary and historical research with linguistic analysis, the project has two different but interrelated objectives.
At first, private correspondences of princesses and princes from the Ernestine part of early modern Saxony which are kept in the State Archives of Thuringia, Saxony, Anhalt, Hesse and Bavaria are traced, digitized, electronically transcribed in full text and annotated. Also, all relevant metadata are recorded and made searchable in a database (Fürstinnen-Briefdatenbank). The single-entry letter metadata are transferred to the respective home archive.
Furthermore, the texts are linguistically annotated and analysed by means of the xml-based software EXMARaLDA. Phenomena like language change, dialect, grammar, lexis, orality-literacy, male and female speech as well as signals of modesty and politeness are especially focussed, the key terms of the respective genderlect are identified and the gender specific features are described.
By integration into the ANNIS database and the LAUDATIO-Repository, the text corpus (600 letters, 262.468 tokens) annotated so far have been provided for further linguistic research. In order to make the letters available also for historical and literary researchers as well as the general public, we are now building up an internet edition of the letter transcriptions according to the TEI P5 guidelines along with the metadata and the digital copies. The platform provided by the ThULB Jena/ collections@UrMEL offers open access and ensures sustainability and data maintenance.
Being a significant part of the cultural heritage not only regarding the central German region but the entire western world, the correspondences have a wide appeal: Apart from being the ancestors of many European royal dynasties, princes like John Frederick I or his eldest son considered themselves champions of Protestantism and the Ernestine electoral dignity. The letters exchanged with their wives while being held in imperial custody testify to their deep piety and strong sense of mission as well as their human frailty and ordinary material needs. Moreover, they offer interesting insights into early modern noble life as well as a wide range of everyday topics like diseases and cures, diet and recipes, child care, gardening or gossip. However, Early New High German itself is an equally important part of the cultural heritage: Given the uncommonness of female literacy and writing in this period, especially the duchesses’ letters represent very rare and vivid monuments of German language.
Due to their digital form, both the text edition and the annotated corpus remain expandable and malleable. Since they are universally accessible, they are open for citizen science and academic collaboration: U pon the readers’ notification, transcription gaps can be filled, version discussed and mistakes corrected; also, annotations, explanations and interpretations can be proposed and hitherto missing identifications of persons and places can be added.
Biography
Vera Faßhauer studied German Literature, English Literature and Art History at the Friedrich Schiller University of Jena where she also did her PhD studies on The Poetics of Ugliness and Caricature in the 18th Century. After having edited several correspondences of the Weimar publisher Friedrich Justin Bertuch in full text, she entered the project Private Ducal Correspondences in Early Modern Germany in 2010. At present, she is digitally editing the diaries of the radical pietist physician Johann Christian Senckenberg at the Goethe University of Frankfurt.
Cristina Bignami / Elena Mucciarelli | The Language of the Objects: “Intermediality” in Medieval South India
We will present the digitization project on the epigraphic corpus from the south Indian State of Karnataka, which has been done in collaboration with the Tübingen University Library. The first step of the work provided the raw data, which are now stored and already available online in the web site of the Tübingen University Library. As a second step of the project, we are working on a digital edition that will offer the relevant documents in an open-source Geo-map with the support the eScience Center of the Tübingen University. Our research question focuses on the inscriptions connected with one of the early Medieval dynasty of south India and the legitimation process that took place during the XI-XII centuries. The comprehension of the text engraved in the stele or in the copper plates is substantially enriched by the artistic study of the temples where the edicts were installed. The interdisciplinary study of epigraphic and artistic documents leads to new readings of the historical process: these two media represent two complementary components of the political agenda of the king. We would like to show an example of this research on “intermediality” and address some of the issues that rise during the process, e.g. the OCR processing of the text as well as the geo-location of the sacred areas. To get an organic view of the historical process it is mandatory to create an integrated system that combines both textual and spatial data. Indeed, the inscriptions were much more than just a “report” to inform about the king’s decisions. The artistic mastery of the sculptors and scribes as well as the literary quality of the texts states that. To underpin their power, these kings opted for the carved stones -be it inscriptions or sculptures- as their unique mark. Through the new form of systematization is possible to fully chart the extension of a king’s dominion over a territory. Can this kind of geo-map also serve as a tool for the popularization of science?
Biographies
Cristina Bignami completed her PhD with a study on Medieval Indian Art at the University of Turin. She is Research Fellow in the project “Kings of the Wild: the re-use of local and Vedic elements in the legitimation process of Medieval Karnataka”, Tübingen University. Her contributions focus on Indian History of Arts and on the History of Medieval South India.
Elena Mucciarelli completed her PhD with a study on semantic developments of the Vedic corpus. Research Fellow in “Kudiyattam: Living Sanskrit Theater in the Kerala Tradition”, Jerusalem and Tübingen University. Principal investigator of “Kings of the Wild: the re-use of local and Vedic elements in the legitimation process of Medieval Karnataka”, Tübingen University. Her contributions focus on the Vedic period and on ritual and cultural aspects of South Indi.
Closing Keynote
Friday, 18 March 2016, 11 am
introduced by Øyvind Eide
Arianna Ciula | Modelling Textuality: A Material Culture Framework | Slides
This keynote will aim at summarising what a material culture approach to the modelling of textuality in a digital environment could entail. While its focus will be on the modelling process of texts-bearing historical documents, its remit is extensible to other cultural artefacts. The modelling process will be discussed following three analytical levels: (1) image and document-based modelling of the material sources; (2) modelling of the materiality of research publications and collections; (3) modelling of the socio-cultural agencies shaping the understanding and historical interpretations of the documents and texts. The three levels will be contextualised with examples taken respectively from (1) digital palaeography; (2) production of hybrid publications for historical research; (3) connection of document-based evidence with further historical data, assertions and interpretations. In addition, being this the closing keynote, its aim would be to collect examples of these three levels from contributions presented to the conference and from the DiXiT fellows projects for what is possible. A research agenda for material culture-based approaches in Digital Humanities, where materiality and semantics of documents are explicitly interrelated, will be suggested. By claiming that modelling is a meaning-making process, it will also emphasise the potential of Digital Humanities research to be socially resonant, for instance, with respect to public history projects.
Biography
Arianna Ciula is Research Facilitator at the Department of Humanities, University of Roehampton, where she supports the departmental research and enterprise strategies and actively contributes to its research profile and networks.
Arianna graduated with BA (Hons) in Communication sciences (computational linguistics) at the University of Siena in 2001; she received an MA in Applied Computing in the Humanities from King’s College London in 2004 and was awarded her PhD in Manuscript and Book Studies from the University of Siena in 2005. She worked on various digital humanities research projects, supervised instruments to fund collaborative research in the humanities and coordinated strategic activities at the European level, including digital research infrastructures. Her personal research interests focus on the modelling of scholarly digital resources related to primary sources. She lectured and published on humanities computing, in particular on digital palaeography and digital philology; she has organised conferences and workshops in digital humanities, and is an active member of its international community (e.g. EADH secretary; ADHO SC member).
Posters
Wednesday, 16 March 2016, 4 – 6 pm
Room 4.016
Manik Bajracharya / Oliver Hellwig / Christof Zotter | Digital Editions of Documents from Pre-Modern Nepal
Ben Bigalke / Ulrike Henny / Pedro Sepúlveda | Pessoa’s Editorial Projects and Publications: The Digital Edition as a New Form of Textual Criticism
Jan Bigalke / Martina Bürgermeister / Daniel Jeller / Stephan Makowski / Gerlinde Schneider / Bernhard Strecker | Monasterium: User-Integration in a DH-Project
Ingo Börner | Critical Edition of Arthur Schnitzler’s Early Works: Digital Workflow
Daniel Bruder / Michael Nedo | Recording, Archiving, Editing, Publishing and Studying Textual Cultural Heritage
Ingo Caesar / Andreas Wagner | The School of Salamanca: Editing an Early Modern Juridico-Political Discourse
Juan José Escribano / Elena González-Blanco / Clara Martínez / Gimena del Rio | EVI-LINHD, a Virtual Research Environment for Digital Scholarly Editing
Tessa Gengnagel / Frederike Neuber | Explorer, Trader, Conqueror? On the Role of the Digital Editor
Costanza Giannaccini | Burckhardtsource.org: Where Scholarly Edition and Semantic Digital Library Meet
Andrew Irving | The Digital Schoolbook (DSB) Project
Chaim Milikowsky | Scholarly Editions of Three Rabbinic Texts – One Critical and Two Digital
Konrad Niciński | TEI Technical Standard: The Experience of Poland
Martin Sievers | Typesetting Using X-Technologies – Dead End or Promising Path? An Overview of Pros and Cons Regarding Critical Editions
Bartłomiej Szleszyński | Nowa Panorama Literatury Polskiej (New Panorama of Polish Literature): How to Present Knowledge in the Internet (Polish Specifics of the Issue)
Manik Bajracharya / Oliver Hellwig / Christof Zotter | Digital Editions of Documents from Pre-Modern Nepal
The foundation of modern Nepal goes back to the middle of the 18th century when the kings of the petty state of Gorkha started conquering surrounding territories and soon ruled over what was to become a national state. The project “Documents on the History of Religion and Law of premodern Nepal”, conducted since 2014 by the “Heidelberg Academy of Sciences and Humanities”, aims at understanding the processes the formation of the state entailed, such as the restructuring of social institutions or the expansion of Hindu rule. Research is based on a corpus of documents available in public and private archives of the Kathmandu Valley.
Among these written documents, which number in hundreds of thousands, particular attention is paid to those relating to religious institutions and to legal and administrative practice. The files held by the National Archives, Kathmandu, and other governmental institutions were described on handwritten catalogue cards and partly microfilmed by the German Oriental Society. However, only some of them have been edited, translated, or studied so far. By applying methods of digital archiving and editing, the project will systematically catalogue, study and selectively edit this unique textual corpus.
In our poster, we will present the digital infrastructure of the project, which consists of three central parts. A MySQL database works as the storehouse for the digitized versions of the catalogue cards that provide detailed descriptions of each document in the collection, along with a bibliographical database and a conceptual inventory. Selected digital catalogue cards are interlinked with TEI encoded XML editions of the respective documents. These editions consist of an abstract, a facsimile, a transcription with different display options (diplomatic, word separated, edited), a translation with notes and commentaries. Both, the database and the XML editions, can be accessed and extended through a web based php frontend. A special focus lies on the collaboration with the scholarly community in Nepal, Europe, and elsewhere. Therefore external users will eventually be enabled not only to access, but also to actively contribute to the refinement of data. Apart from this hybrid database, which has a pioneering character in the research in South Asian documents, the poster will present the axes of future research of our work, which includes developing an automatic lemmatizer, an ontology of juridicial terms and an OCR program for the Nepalese documents.
Biographies
Manik Bajracharya comes from Nepal and has a PhD from Aichi Gakuin University, Nagoya, Japan. He has published a three volume work on the “Wright’s Chronicle of Nepal” in 2015. Currently, he is a researcher in the project “Documents on the History of Religion and Law of Pre-modern Nepal” at the Heidelberg Academy of Sciences and Humanities.
Oliver Hellwig is Indologist with a special focus on quantitative language analysis. Current areas of research comprise medieval Indian alchemy, quantitative stratification of Indian epics, and the semi-automatic semantic analysis of Sanskrit texts.
Christof Zotter studied Indology and Ethnology. Combing textual and fieldwork, he worked on Hindu life-cyle rituals in Nepal. Currently, he is the head of the editorial programme of the project “Documents on the History of Religion and Law of Pre-modern Nepal” at the Heidelberg Academy of Sciences and Humanities.
Ben Bigalke / Ulrike Henny / Pedro Sepúlveda | Pessoa’s Editorial Projects and Publications: The Digital Edition as a New Form of Textual Criticism | Poster | Slide (Poster Slam)
A digital edition of Fernando Pessoa’s editorial projects and publications in lifetime is being established through a collaboration between scholars from the Institute of Literature and Tradition (IELT) of the New University of Lisbon and the Cologne Center for eHumanities (CCeH) of the University of Cologne. The edition focuses on the contrast between the potential character of Pessoa’s numerous lists of editorial projects and his actual publications in lifetime. The digital format allows for a combination of different editorial procedures, proposing a new form of textual criticism within the editing of Pessoa’s work.
Due to the existence of several textual variants and hesitations, past editions in book form define themselves by following either the first or the last version of a text, or by choosing from the existent variants from a hermeneutical standpoint. The digital edition offers several coexistent forms of transcription: a diplomatic transcription, including all variants, hesitations and passages later rejected by the author and following line breaks presented in the original document; a first version of the text, as established by the author and including expanded abbreviations; the last and non-rejected version of the text as well as the possibility for the reader to establish a customized version, by choosing from the mentioned elements. The texts are presented together with the digital facsimiles. In addition to the critical establishment of the text by means of a transcription, a commentary describing material aspects and contextual information is added to the documents. Furthermore, mentioned authors and works are identified in the texts, allowing for the formalisation of links between the editorial projects and the actually published texts. A general index of persons and mentioned texts which goes beyond Pessoa’s own work opens the material up and prepares connections to other resources. A chronology of the documents is presented in the form of an interactive timeline, aiming to chart the history of Pessoa’s projects and publications in his lifetime.
This presentation of the texts offers a new access to Pessoa’s works, by focusing both on a significant part of his literary archive, held by the Portuguese National Library, and his published poetry in journals and magazines. The various approaches combined in this digital edition allow for an adequate understanding of the dynamics of Pessoa’s writings and make them available to Pessoa scholars as well as to the public.
Following the typology proposed by the Institute of Documentology and Scholarly Editing (IDE), one could say that this edition combines procedures from a documentary, a diplomatic, a genetic and an enriched edition, overcoming previous oppositions between different editorial approaches to the poet’s work and adding new ones that were hardly possible in a print edition.
Biographies
Ben Bigalke studies Information Science and Educational Science at the University of Cologne. As a student assistant, he is involved in several Digital Humanities projects, inter alia The Digital Edition of Fernando Pessoa and the Corpus of English Religious Prose.
Ulrike Henny studied Regional Sciences of Latin America at the University of Cologne and the Universidade de Lisboa. During the last years, she has been working on the development of Digital Humanities projects at the Cologne Center for eHumanities, primarily digital archives and editions. Currently, she is a research associate at the University of Würzburg and working on her dissertation about subgenres of the nineteenth century Spanish-American novel.
Pedro Sepúlveda is a Post-Doctoral Fellow and Lecturer at the College for Social and Human Sciences, New University of Lisbon (Universidade Nova de Lisboa). He published in late 2013 a monograph entitled Os livros de Fernando Pessoa (Ática). He is the executive coordinator of the Research Project “Estranging Pessoa: An Inquiry into the Heteronymic Claims”, supported by the Portuguese Foundation for Science and Technology (FCT) from 2013 onwards. Amongst his research interests are the literary and philosophical Modernity and the History of the Book. He also serves as an editor of Pessoa’s works and a translator of German speaking writers into Portuguese.
Jan Bigalke / Martina Bürgermeister / Daniel Jeller / Stephan Makowski / Gerlinde Schneider / Bernhard Strecker | Monasterium: User-Integration in a DH-Project | Poster
Monasterium is the biggest digital archive of charters in Europe. Founded in 2001, it includes roughly one million data records from the Middle Ages and early modern times, but the platform is not simply a viewer for these charters; Monasterium has been supplied many data hosts and has a policy for an open minded data integration. Due to this, it supports a steady growth of the entire dataset and makes it flexible concerning the tapping depth. At this point user integration becomes a crucial factor for the creation and editing of data inside the Monasterium platform. This user integration works with the help of
- collaborative events (so-called “MOMathons”)
At these events, users have the possibility, based on some kind of crowdsourcing, to participate in the development of the dataset and give feedback to the developers. - user-friendly tools for editing charters like WYSIWYM-editors,
A XML-based WYSIWYM-Editor was created to ensure that the user is able to use the platform without any obstacles. While using this editor, the user can just focus on the recording of the data. - visualization of referred knowledge with georeferencing
To give the user a quick overview about a collection of the archive, we have implemented a georeferencing-Tool in the MOM-CA-Framework. This functionality allows the user to get a quick impression of the localization based on the dataset of the charter. - better retrieval via “Drill Down”-components.
Because of the size of this unique set of data, ordinary search- and order functionalities are reaching their limits. That is why the Monasterium-team focuses on new possibilities to improve the document search based on visualization and filtering of specific attributes of a charter. Users will be integrated by querying the database with a specific scientific question and because of this “Drill Down”-approach they will get just the results as expected.
This poster should give a short impression of the current status of development.
Biographies
Jan Bigalke and Bernhard Strecker are working on the Monasterium.net-Project. They are members of the Cologne Center for eHumanities (CCeH).
Martina Bürgermeister is member of the scientific staff at the “Austrian Centre for Digital Humanities” at the University of Graz, Austria since 2014. She is also working on the “Illuminated Charter Project” hosted by the University of Graz.
Daniel Jeller is working at the International Centre for Archival Research (ICARUS). He is the project manager of the Monasterium.net-Project.
Stephan Makowski was the project manager of a funded digitalization project from 2013 to 2015. Since March 2015 he is a senior programmer for the Monasterium.net-Platform and a member of the Cologne Center for eHumanities (CCeH).
Gerlinde Schneider is working at the “Austrian Centre for Digital Humanities“. She is working on the “Digital Research Infrastructure for the Arts and Humanities“-Project at the University of Graz.
Ingo Börner | Critical Edition of Arthur Schnitzler’s Early Works: Digital Workflow | Poster
The poster “Critical Edition of Arthur Schnitzler’s Early Works. Digital Workflow” describes the technical workflow for the creation of the historical-critical edition of the early works (1880–1904) of the Austrian modernist writer Arthur Schnitzler (1862–1931). This edition is edited by Konstanze Fliedl of the University of Vienna and funded by the Austrian Science Fund (FWF). Five print volumes were published in the first project (2010–2014).
With the start of the follow-up project in October 2014 (Arthur Schnitzler – Critical Edition [Early Works] II), a new digital workflow has been implemented in which the data is now encoded according to the TEI P5 Guidelines, and then transferred to the print edition with XSLT (XML to Adobe Indesign for the highly diplomatic transcriptions and Latex for the printed texts).
The central question this poster examines is that of how to implement new digital methods in an ongoing editorial project; it provides a practical report of this continuous conversion process. In particular, the poster focuses on how a traditional, print-based editorial project already in progress can benefit from digital methods that have been developed within the context of digital scholarly editing, e.g. text encoding and computer automated collation.
Biography
Ingo Börner studied Russian and German studies in Vienna and Moscow. He currently works as a research and teaching assistant at the Department of German studies at the University of Vienna, where he is involved in the creation of the “Critical Edition of Arthur Schnitzler’s Early Works”.
Daniel Bruder / Michael Nedo | Recording, Archiving, Editing, Publishing and Studying Textual Cultural Heritage
Based on methods developed for the print edition of Wittgenstein’s writings in the Wiener Ausgabe – itself based on an electronic edition – generally applicable tools are being developed, based on interoperable data formats, which will improve usability and in particular longevity, the most serious problem of today’s data repositories with their short ‘shelf life’, limited to about 20 years. These methods and tools have the potential to transform the study of literature, both ancient and modern, as well as the history of ideas and of science, since they all depend ultimately on the access to, and the study of, historical documents.
In 1988 the Text Encoding Initiative (TEI) Guidelines were proposed to establish best practices for encoding textual transcriptions for scholarly editions and other forms of text. Constraining the tagging of historical texts to standardised values should lead to the development of reusable software to process them. But leading figures within the TEI community have acknowledged that tags subjectively applied, resulting in rich transcriptions of historical documents, means this data is not reusable without being adapted for different applications, that this data cannot be uniformly searched, that these formats “offer no advantage over plain-text, HTML or EPUB texts”; problems which have been exacerbated by the practice of using markup not only for recording simple textual properties, but also for identifying and describing a document as a digital object, for annotation by scholars or general users, and for recording differences between versions or within drafts of a work, where the non-interoperable parts are mingled with highly interoperable data.
To achieve interoperability of electronic repositories, to improve usability and shelf life for electronic textual data, future electronic editions need to comply with the following criteria:
- The underlying textual data formats, in which written cultural inheritance isrecorded and archived must be free of documentary metadata and scholarly annotations.
- Recording and archiving cultural inheritance must, as far as possible, be independent of the computer hardware and software, a precondition for a long shelf life of data repositories, comparable to that a printed book.
- Text files must be stored in widely used and upgradable standards, such as HTML or EPUB, but also as plain text. Those files should have a minimum of encoding, representing only such structures as cannot be computed from the text itself; for maximum longevity they should also be stored as UniCode plain text, with external mark-up pointing to them from the outside.
Some tools developed for the Wittgenstein edition will be shown in a representation together with their application in a philological-philosophical research project.
Biographies
Daniel Bruder hat 2004 ein Studium der Vergleichenden außereuropäischen Religionswissenschaft, Ethnologie und Tibetologie an der Universität München (LMU) mit Spezialisierung auf schriftlose Kulturen und deren Übergänge zur Schrift sowie Cyberanthropology absolviert. Mitarbeit an diversen Editionsprojekten (hypernietzsche/nietzschesource.org, später Wittgenstein-Editionen/Suchmaschinen), 2006 Wechsel zur Computerlinguistik. 2011 Praktikum bei Apple (Cupertino, Kalifornien) im Bereich Dokumentation, Übersetzung und “Deep Localization”. 2012 Beginn der Magisterarbeit, 2013 Abschluss in Computerlinguistik, Religionswissenschaft und Ethnologie; Magister Artium auf dem Gebiet der Finite State Automata, Entwicklung einer neuartigen Index-Struktur zum detaillierten Erfassen, dem Indexieren und Durchsuchen von Texten. Seit 2010 Kooperationen mit dem Centrum für Informations- und Sprachwissenschaft (CIS) an der LMU München (Dr. Max Hadersbeck), dem Wittgenstein Archiv Bergen und dem Ludwig Wittgenstein Trust in Cambridge. 2013-2015 wissenschaftlicher Mitarbeiter am Forschungsprojekt Wittgenstein Advanced Search Tools (WAST) im CIS an der LMU.
Michael Nedo was born 1940 in Bautzen, Germany; toolmaker apprenticeship. Fled to West-Germany in 1957; worked as toolmaker in Stuttgart, 1961 Abitur (A-Levels). Studied mathematics at Tübingen University, changed to experimental physics; 1967 dissertation on Lamb-Shift measurements. Changed to zoology, Max-Plank Institute for Bioacoustics, dissertation on the acoustic behavior of the common desert locust Shistocerca Gregaria. Since 1978 director of the Wittgenstein Archive at Tübingen University; 1981 continuation of the editorial work at Trinity College, Cambridge. Since 1991 director of the Wittgenstein Archive Cambridge and the Ludwig Wittgenstein Trust, editor of Wittgenstein’s writings in the Wiener Ausgabe.
Ingo Caesar / Andreas Wagner | The School of Salamanca: Editing an Early Modern Juridico-Political Discourse
The fundamental importance of the School of Salamanca for the early modern discourse about law, politics, religion and ethics is widely acknowledged among of philosophers and legal historians. During the 16th and 17th centuries, this academic movement reached not only the most far-flung cities of the Spanish monarchy, be it Mexico, Madrid or Manila: its influence also spread to universities in the protestant territories of the Ancien Régime. Europe’s intellectual history, history of political thought, and legal history cannot be understood adequately without being aware of the School of Salamanca as an almost universal intellectual reference point.
Nevertheless, the internal differentiation of the School and the assessment of its intellectual influence remains a much discussed topic until the present day. On the other hand, when compared with the comprehensive outlook that the early modern authors themselves shared, the connections between persons, texts, and disciplines threaten to become lost in the picture that today’s fragmented disciplinary discourses convey.
To help address such problems, our project aims to establish free and easy access to primary sources, their concepts and contexts. As a foundation of our work we will build a digital text corpus including more than 120 works of the Salmantine jurists and theologians in selected prints from the 16th and 17th centuries. The high-resolution scans will be complemented by the full text of the featured works, taking advantage of interlinking possibilities and providing flexible search functionalities. Based on these sources, we will also compose a handbook of about 300 essential terms of the Salmantine School’s juridico-political language, including biographical information about the authors. These articles will be linked to each other, to the source texts, and to authority databases, enabling easy access to information about concepts, contexts, and authors.
The paper presentation will introduce the project and its web interface, and it will illustrate how it is precisely the interlinking of information that allows reconstructing an early modern academic-cum-political discourse network as such. This capability comes at a price with regard to the waiver of manuscript or variant prints textual criticism, but it also exceeds the traditional edition’s purpose of enabling the reading and hermeneutical interpretation of isolated texts.
Biography
Andreas Wagner is research associate at the project “The School of Salamanca” of the Academy of Sciences and of Literature Mainz, working in the Institute for Philosophy of Goethe University Frankfurt/Main. He has obtained his PhD in philosophy with a thesis about contemporary political philosophy in 2008 and has since been working on early modern philosophy of law in Frankfurt and Hamburg. Together with Ingo Caesar, he is also one of the developers of the project’s digital edition website.
Juan José Escribano / Elena González-Blanco / Clara Martínez / Gimena del Rio | EVI-LINHD, a Virtual Research Environment for Digital Scholarly Editing | Poster | Slide
Virtual Research Environments (VREs) have become central objects for the digital humanist’s community, as they help global, interdisciplinary and networked research taking profit of the changes in “data production, curation and (re‐)use, by new scientific methods, by changes in technology supply” (Voss and Procter, 2009: 174-190). DH Centers, labs or less formal structures such as associations benefit from many kinds of VREs, which facilitate researchers and users by providing a place to develop, store, share and preserve their work, thus making it more visible. The implementation of each of these VREs is different, as Carusi and Reimer claim (2010), but there are some common guidelines and standards generally shared (as an example, see the Centernet map and guidelines of TGIR Huma-Num 2015).
This poster presents the structure and design of the VRE of LINHD, the Digital Innovation Lab at UNED (http://linhd.uned.es), and the first Digital Humanities Center in Spain. It focuses on the possibilities of a collaborative environment for (profane or advanced) Spanish-speakers scholarly digital editors. Taking into account the language barrier that English may suppose for a Spanish-speakers scholar or student and the distance they may encounter with the data and organization of the interface (in terms of computational knowledge) while working with a scholarly digital edition or collection, LINHD’s VRE comes as a solution for the virtual research community interested in scholarly digital work.
In this sense, our project dialogues and aims to join the landscape of other VREs devoted to digital edition, such as Textgrid, e-laborate, etc. and, in a further stage, to build a complete virtual environment to collect and classify data, tools and projects, work and publish them and share the results. Therefore, the key of our VRE is the combination of different open-source software that will enable users to complete the whole process of developing a digital editorial project. The environment is up to now divided into three parts: 1) A repository of data to (projects, tools, etc.) with permanent identifiers in which the information will be indexed through a semantic structured ontology of metadata and controlled vocabularies, using the software of LINDAT-Clarin and complementing it with digital humanities metadata. 2) A working space based on the possibilities of eXistDB to work on text encoding, storing and querying, Omeka and WordPress, plus some publishing tools (pre-defined stylesheets and some other open-source projects, such as Sade, Versioning machine, etc.). 3) A collaborative cloud workspace which integrates a wiki, a file archiving system and a publishing space for each team with a unified login system.
Biographies
Juan José Escribano is Computer Science Engineer at the Universidad Politécnica of Madrid (2005) and he works as a programmer since 2001. His current job is as a programmer and analyst in the development area of the company Unidad Editorial. He is also studying Spanish Literature at UNED since 2005 and collaborates with LINHD since 2014.
Elena González-Blanco is a Faculty member of the Spanish Literature and Literary Theory Department at Universidad Nacional de Educación a Distancia UNED (Open University) of Spain in Madrid. Her main research and teaching areas are Comparative Medieval Literature, Metrics and Poetry, and Digital Humanities. She holds a Ph.D in Spanish Literature, a M.A. in Digital Libraries and Information Systems, a M.A. in Spanish Philology and an M.A. in Classics. She is the Director of the Digital Humanities Lab at UNED: LINHD (Laboratorio de Innovación en Humanidades Digitales) http://linhd.uned.es, constituent member of the first Clarin-K Center, and organizer of the last DayofDH 2015 http://dayofdh2015.uned.es. She has been the Academic Secretary from the Faculty of Philology at UNED (2011-12) and she is the Director of the professional programs Experto Profesional en Humanidades Digitales: http://linhd.uned.es/p/titulo-propio-experto-profesional-en-humanidades-digitales/ the Experto Profesional en Edición Digital Académica http://linhd.uned.es/p/titulo-propio-experto-en-edicion-digital-academica/ and the coordinator of the institutional UNED linked data project UNEDATA http://unedata.uned.es.
Clara Martínez is a Faculty member of the Spanish Literature and Literary Theory Department at Universidad Nacional de Educación a Distancia UNED (Open University) of Spain in Madrid. She completed her PhD at UNED on comparative literature, but she has also taught and researched in other European universities such as Bergamo or Toulouse. Her main research line is Spanish metrics, and she specially focuses on contemporary poets. She is a researcher of the ReMetCa group (Digital Repertoire of Medieval Spanish Metrics). Her main publications are the books on metrics and poetry of Antonio Colinas (2011 and 2013). She won the price Mariano Rodríguez for young researchers.
Gimena del Rio has a PhD in Romance Philology (Universidad Complutense de Madrid) with a critical edition of King Dinis of Portugal’s Songbook. Researcher at the Seminario de Edicion y Crítica Textual (SECRIT-IIBICRIT) of the National Scientific and Technical Research Council (CONICET), Buenos Aires, Argentina and External professor at LINHD-UNED (Madrid). She gives courses on Romance Philology and Digital Humanities at the University of Buenos Aires and LINHD. Her main academic interests deal with the scholarly edition and study of the Medieval lyrical poetry and the development, use and methodologies of scholarly digital tools. She has been working since 2013 on the creation of a Digital Humanities community in Argentina and is nowadays the vice-president of the Asociación Argentina de Humanidades Digitales (AAHD). She organized the I National Conference on Digital Humanities in Buenos Aires last year. She coordinates the Argentinian digital projects Diálogo Medieval (Medieval Dialogue Poetry) and Methodologies of Digital Tools applied to Social Sciences and Humanities at CAICYT-CONICET, and is part of the Spanish digital projects Repertorio Digital de la Métrica Medieval Castellana (ReMetCa) and Bibliografía de Escritoras Españolas, BIESES, among others.
Tessa Gengnagel / Frederike Neuber | Explorer, Trader, Conqueror? On the Role of the Digital Editor
Willard McCarty has employed metaphors and stories to “suggest the beginnings of what might be called a new professional myth” for the Digital Humanities. Such a “myth” can evoke a clearer sense of self which in turn is instrumental in establishing curricula and institutionalizing Digital Humanities. McCarty envisions different landscapes to locate interdisciplinarity. Our poster will expand on his imagery of an archipelago: islands as disciplines and the quest for knowledge as a journey through uncharted waters. The focus will be narrowed down to the field of digital editing and the role of the digital editor in particular.
In our understanding, a digital editor is someone who plays an active and essential part in the conceptualization and implementation of digital editions, not only familiar with the material but also aware of the technical matters involved. More than that, he is able to combine his competences to fully exploit the potentials of the digital to create an edition centered around the specific needs of the individual materials while accommodating diverse research interests as best as possible.
When Peter Robinson asked Digital Humanists to get out of textual scholarship, it was a proclamation to the traditional disciplines to defend their territory by absorbing the digital turn completely, becoming aware of its implications for what they do, how they do it, and who they are. However, required competences still have not found their way into teaching and learning at universities, leaving the scholar to attend extracurricular workshops or gain skills autodidactically. Even if the digital editor succeeds in conquering competences from both scholarly editing and Digital Humanities, the traditional disciplines will presumably perceive this as a loss of expertise rather than recognize cross-disciplinarity as an expertise in itself. Thus, the digital editor risks losing the academic accolades he may have received, had he continued a more “traditional” path of scholarship in his home discipline. His best prospect is to obtain the role of a “craftsman” who facilitates the trade between scholars and IT.
The image we are painting of the digital editor and his role within established disciplines might seem pessimistic but is intended to inspire a conversation about the status quo. By pushing McCarty’s “sea-going” metaphor further, visualizing the archipelago of the humanities and the navigating digital editor in it, we wish to raise the following questions:
Where are we – within other disciplines, outside or in between?
Where are we invited to cast our anchor?
And who are we – explorers, traders, or conquerors?
Biographies
Tessa Gengnagel studied History and Latin Philology of the Middle Ages (B. A.) at the University of Freiburg and European Multimedia Arts and Cultural Heritage Studies (M. A.) at the Universities of Cologne and Graz. In October 2015, she started her PhD under the supervision of Prof. Manfred Thaller with a fast track scholarship from the a.r.t.e.s. Graduate School for the Humanities Cologne. She also works in the project management of the Marie Curie ITN DiXiT.
Frederike Neuber completed a Bachelor’s in Italian Philology, History and Art History and a Master’s in Textual Scholarship at the Freie Universität Berlin and the Università degli Studi Roma Tre. Since April 2014, she is a part of the Marie Curie Network DiXiT working at the Centre for Information Modelling at the University of Graz in Austria. In her PhD, she explores the potentials of digital scholarly editions for typographical studies in Stefan George’s poetical work.
Costanza Giannaccini | Burckhardtsource.org: Where Scholarly Edition and Semantic Digital Library Meet| Poster
Burckhardsource.org is a semantic digital library created within the project “The European correspondence to Jacob Burckhardt”, funded by the European Research Council and coordinated by Prof. Maurizio Ghelardi (Scuola Normale Superiore, Pisa). The task has come to its final steps and offers today the scholarly edition of the correspondence to the Swiss art historian. This corpus reconstructs one of the most important matches of the nineteenth century. Written by about four hundred correspondents in German, Italian, English and French, the letters cover a time span ranging from 1842 to 1897 and witness a period filled with major cultural transformations.
To understand the manifold character of Burckhardtsource, it is essential a brief digression on the technologies used in the Philological Version and on the corresponding Front-end aspects, on its multilayer structure as well as on the different visualisation proposals.
Beyond an accurate manuscripts analysis, the platform offers specific technical tools conceived to add further information to texts thanks to the use of the semantic annotation. Indeed, the Semantic Edition illustrates the concrete use of Pundit, an innovative tool to annotate web contents based on Linked Data technologies. The adoption of this innovative tool provides additional information to text parts thanks to the link to specific and recognised Linked Data providers, Museums and Collections, or to a Customised Vocabulary (Korbo). Museums, Libraries and Archive are in close connection to the platform and the collaboration with the Marburg Bildarchiv is a paradigmatic example. On the other hand, the Semantic Web basket manager allows, among other features, to share concepts and knowledge in working groups. Special attention must be dedicated to two cutting-edge tools recently implemented: the advanced semantic search and the geographical search.
In conclusion, the platform Burckhardtsource.org, final product of the ERC project, demonstrates how all the different information added to transcriptions, such as annotations, metadata, LOD imported data, as well as the dates included in all the LOD linked resources, can be elaborated, retrieved and displayed in several ways.
Burckhardtsource.org moves its first and fundamental steps from the traditional Scholarly Edition, going then forwards and taking advantage of the ductility and the tools offered by modern technologies, in a connection and mix of tradition and innovation. The contribution to a deeper and wider interpretative degree and shared knowledge helps create a possible unlimited sequence of interconnections and consistent extensions.
Biography
Costanza Giannaccini, Graduate of Foreign Languages and Literature (Pisa), has a PhD in Cultural Memory and European Tradition (Pisa). Since 2012 she works as Post-doctoral Research Fellow (ERC – SNS) in the ERC-Advanced Project “The European Correspondence to Jacob Burckhardt”.
Andrew Irving | The Digital Schoolbook (DSB) Project
The DSB Project studies the history of pre-modern European education through its surviving schoolbooks ranging from 300 to 1600 AD. Humble in appearance and containing elementary writings, these books consist of texts which shaped the thought of children ˗ and ultimately helped mold them into adults ˗ for more than a millennium. The core text of these schoolbooks is the second-century Distichs of Cato, a set of concise moral precepts attributed to the Roman moralist Cato the Elder. These precepts emphasize the power of human agency, prudence, discipline, rationality, and above all the importance of lifelong learning. Over centuries from late antiquity to the early modern period educators in various regions of Europe added commentaries and auxiliary texts to explain and expand upon these proverbs in manners which mirror contemporary political, religious, and social concerns; however, the core text changed little.
Though virtually unknown to modern learners, the Distichs of Cato was the beginning text for countless generations of school children for both Latin and moral education. Its popularity testifies to the fundamental importance which European educators assigned to the values embodied by these precepts, the humanistic quality of which was developed in, fostered by, and transmitted through late antique and medieval classrooms. Moreover the Distichs function as a kind of kernel of a group of educational materials, some of which explicitly were written in response to the Distichs, and others of which came to be copied with the Distichs in various combinations as “travelling companions” of the base text.
The complexities of the evolution of the text itself and of its use, the size of the corpus of manuscript witnesses of the text, its commentary and transmission (well over 800 manuscripts from 23 countries dating from the 8th to the 17th century), and the pertinence of the subject to a range of disciplines from grammar to political science, have prompted us to turn to DH tools and methodologies, which have shown themselves particularly adept at fostering collaboration and interdisciplinary dialogue, and are well-suited to study and visualization of hybrid and fluid phenomena, and the analysis of large datasets.
While much groundwork has been completed using traditional methodologies, we are still at the early stages of the design, planning and implementation of a fully-fledged DH project. The poster will present key components of the DSB, an outline of its goals and scope, and selected preliminary findings regarding the evolution of the text and its commentary tradition.
Biography
Andrew Irving, a native of New Zealand, received his doctorate in Medieval Studies from the Medieval Institute of the University of Notre Dame, with his dissertation, The Eleventh-Century Gospel Books of Montecassino: An Archaeology in 2012, a section of which has been published in Scriptorium. His research interests center on liturgical manuscripts and material aspects of their production and use. After a year as a post-doctoral research associate at Yale’s Institute of Sacred Music developing a long-term project on design changes in mass books in the twelfth-century, he taught early and medieval church history for two years at The General Theological Seminary in New York. He is currently a researcher for the Notre Dame digital project, “The Digital Medieval Schoolbook”, which explores the transmission, translation, and commentary tradition of the Disticha Catonis from its composition until the seventeenth century.
Chaim Milikowsky | Scholarly Editions of Three Rabbinic Texts – One Critical and Two Digital
| Poster
- A critical edition of Seder Olam (Jerusalem; Yad Ben Tzvi, 2013)Seder Olam is an early rabbinic chronography of the biblical period whose raison d’etre is dating events not dated in Bible (e.g., the Tower of Babel and the Binding of Isaac) and resolving chronological cruces. It is the earliest preserved rabbinic composition, and later works cite it thousands of times. No critical edition of the entire work has ever been published.I established the text of the edition using classic stemmatological methods. It is based on all extant manuscripts and early printed editions.
- A synoptic line-under-line edition of Vayyiqra Rabba (installed on Bar Ilan University’s web server c. 2005)Vayyiqra Rabba is a homiletic-cum-exegetic early midrashic work with Leviticus as its base, and is a central repository of rabbinic ideology and theology.The digital edition was input using plain-text (Hebrew) ASCII; care was taken to add no codes or coding (forestalling incipient obsolescence).
- The Friedberg Project for Babylonian Talmud Variants (‘Hachi Garsinan’, commenced c. 2012; I chair the Academic Advisory Board)The project will encompass all Babylonian Talmud textual witnesses, i.e. Genizah fragments, manuscripts, early printings, binding fragments and other fragments found in public libraries and private collections all over the world and will include all tractates of the Babylonian Talmud. It presents high quality digital images of all original text-witnesses, accompanied by precise transcriptions of the text in the image. It will display the text-witnesses by column synopsis as well as by row synopsis, dynamically, enabling the user to choose which variants to highlight and which to omit, while emphasizing the differences between the text-witnesses, using advanced visual methods that will help the user complete his quest quickly and efficiently. It will also integrate additional functions including full text search on all text-witnesses, as well as save, copy and print options, personal workspace, etc. A partial version began operation about a year ago and is freely available (requires registration).
Biography
Chaim Milikowsky is a professor in and Chair of the Talmud Department at Bar Ilan University. He received his Ph.D. from Yale University in Post-Biblical Jewish History and Literature in 1981. His interests focus on rabbinic literature and Jewish intellectual history of the Hellenistic and Roman periods; he has also published on textuality and editorial practice.
Konrad Niciński | TEI Technical Standard: The Experience of Poland | Poster
Nowa Panorama Literatury Polskiej (New Panorama of Polish Literature, NPLP.PL) is a platform for presenting research results in the digital environment; it is a part of the Digital Humanities Centre at the Institute of Literary Research. Interdisciplinary team of New Panorama of Polish Literature is currently working on the second Polish issue of TEI technical standard and the first, which will be adjusted to the edition of nineteenth and twentieth century collection of literature, including non-fictional forms, as letters and diaries. The first digital edition in this series will consist of 20th century letters of poets attached with the leading Polish-emigré magazine (Wiadomości), Jan Lechoń and Kazimierz Wierzyński, and the magazine’s editor, Mieczysław Grydzewski. Probably the next work of the team will be edition of Bolesław Prus’ last novel, Dzieci (Children), containing the problems, which the print edition is still unable to resolve.
The poster will present some problems encountered during both work on the first of these two editions and the preparation to the second one, especially concerning issues like:
- Adapting TEI standard to the Polish literary specifics.
- The letters written by Jan Lechoń and Kazimierz Wierzyński: key elements of the edition.
- Advantages of digital edition compared with Polish specifics of scholarly edition, particularly of critical edition.
- Advantages and difficulties in adapting scholarly edition (and editors) to the demands of the digital environment.
Biography
Konrad Niciński is a lecturer in the Faculty of Polish Studies (Department of Baltic Studies) at Warsaw University (UW), co-worker of the Digital Humanities Centre (Centrum Humanistyki Cyfrowej, CHC) at the Institute of Literary Research of the Polish Academy of Sciences (Instytut Badań Literackich PAN). His research interests include history of polish culture in the Modernism period and the non-fictional literature, mainly letters and diaries.
Martin Sievers | Typesetting Using X-Technologies – Dead End or Promising Path? An Overview of Pros and Cons Regarding Critical Editions | Poster
The altered text reception by readers as well as the modified publication processes at publishing houses largely influence the way academic research is published. This is especially true for textual scholarship, where the standard book publications are increasingly substituted by hybrid or born-digital publications.
Along with that a radical transition of technical requirements and standards has taken place. This trend is even increased by the fact, that more and more researchers start publishing research result on their own, e. g. as part of open access initiatives. The magic word on both sides is XML. For publishers the media-neutral format of the meta language is an ideal starting point for “cross-media publishing” (multi-format publishing). On the researchers’ and authors’ side – especially in the Digital Humanities – the widely spread TEI standard means, that different types of information (data) are provided in a standard format and thus are available to many recently developed software tools as an exchange and output format.
However, a big problem often remains open: how does one get the annotated data into the final publication? Typesetting tools like XML-Print or Apache FOP try to solve this problem within the “X-technologies”.
Having a closing look at different existing tools – both open source and commercial ones – it becomes quite obvious, that the requirements of academic typesetting have not been taken into account (yet?) to the needed extent. The reason is, that standards like the X-technologies are primarily industry-driven and corresponding software consequently meets only the requirements of a specific – admittedly large – non-academic target group. Those requirements motivated from a rather academic perspective, however, regularly get much too little attention. Kevin Brown, Executive Vice President of Sales & Marketing at RenderX put it this way on the „xsl-list“:
One, in a few short specs it was nailed pretty well and it does what 90 % of the people want right now for print. There is really little to add to it to cover the full intention of what it should be – a standard for the representation of Formatted (print) output. […] XSL FO will survive for a long time for those that require true print output and for a long time it will be the only Industry Standard way of doing it.
As a consequence modern virtual research environments like FuD or ediarum started to integrate established, but not necessarily XML-based open source typesetting tools like TeX or TUSTEP to provide a formatted version for proofreading or even a camera-ready copy for a book publication.
The poster illustrates the question, to what extent the approach of a media-neutral workflow in textual scholarship is at all possible and reasonable. This is achieved by examining existing standards and tools regarding their capability for digital as well as for printed publications.
Biography
Martin Sievers studied Applied Mathematics in Trier and offers consulting services regarding the use of the typesetting software TeX. As president of the German speaking TeX user group (DANTE) he stands up for the distribution and development of the opensource software. For six years he has as well been working as a research associate at the Trier Center for Digital Humanities. There he is principally involved in XML typesetting, font development and typography.
Bartłomiej Szleszyński | Nowa Panorama Literatury Polskiej (New Panorama of Polish Literature): How to Present Knowledge in the Internet (Polish Specifics of the Issue) | Poster
Nowa Panorama Literatury Polskiej (New Panorama of Polish Literature, NPLP.PL) is a platform for the presentation of research results in the digital environment. It is a part of the Digital Humanities Centre at the Institute of Literary Research of the Polish Academy of Sciences. It consists of separate collections, each telling a different “scientific story” and using a different form to present content. Interdisciplinary team of New Panorama of Polish Literature includes literary and culture researchers, graphic designers and typographers.
This poster will present some problems encountered during work on creating two collections – PrusPlus (dedicated to life and work of Bolesław Prus, the famous polish writer from II half 19th century) and Atlas Romantyzmu Polskiego (The atlas of polish romantic period, concentrated on various spaces of biographies of this period writers and works) and how they have been overcome, especially concerning issues like:
- Interdisciplinary team – advantages and difficulties in managing, how to create team, how to deal with programmers and technical issues.
- Popular or scientific – how to address published material? Can a digital collection be popular and scientific at the same time?
- Stylization, illustrating, visual identification – how to make a website look “scientific” and attractive at the same time.
- Space and text – how map can be used to enrich scientific narration.
- A story or an encyclopedia – two models of presenting scientific material.
- Polish specifics of digital humanities – ways of funding digital humanities, problems in cooperation with museums and archives
- How to make digital collections immersive, how to plan controls and functional features.
- How to avoid anachronisms.
Biography
Bartłomiej Szleszyński works in Institute of Literary Research of the Polish Academy of Sciences (Instytut Badań Literackich PAN). He conducts research on literature and culture of the 2nd half of 19th century (inter alia on its reception in contemporary culture and on colonial threads in polish culture of that period). He also studies modern visual and audiovisual narratives (comic books, video games) and is the manager of New Panorama of Polish Literature (Nowa Panorama Literatury Polskiej, NPLP.PL), a part of the Digital Humanities Centre (Centrum Humanistyki Cyfrowej, CHC) at the Institute of Literary Research of the Polish Academy of Sciences.


